I’m Chie Furusawa from Dwango Media Village. In this article, I introduce a technique that can change the facial expressions and head orientations of a character based on a single image. The demo generates three types of motion animations from a single front-facing character face image. Please try the demo below first. If you prefer to read the method details first, please proceed.
The demo has ended.
In the following video, you can see the steps required to operate the demo:
An animated video of the input image will be generated in about 10-60 seconds. The result video tag is ‘#TalkingHead’. Please share it. When sharing on social media, make sure that the image used does not violate any regulations.
From finely hand-drawn characters to loosely drawn characters and characters with 3D models, I think the results will be quite nice! Below are some examples. The second and third rows are the author’s drawings, and they move well despite being casually drawn.
This article and the demo are based on the technique of Talking Head Anime from a Single Image by [Khugurn]
The above article explains the background of this technology, system overview, and implementation details very carefully. Additionally, there are videos related to the technology.
A little after the introduction of the technology, the source code to run the demo was also released. In that demo, you can move the input character’s face image by adjusting the face parameters sliders or synchronize the character with human facial movements. However, a GPU is required for interactive operation.
In this article, I attempted to reproduce the results using my own dataset. The demo is provided so that even those without a GPU can enjoy this technology. In the following explanation, the implementation by Khungurn is referred to as “Khungurn’s implementation.”
The technology introduced in this article can change the facial expressions and head orientations of a character based on a single image. As the phrase ‘only one image’ suggests, changing 3D information like head orientation from 2D information like images is a challenging theme. There are broadly two methods to change facial expressions and head orientations based on character images. One is the 3D-based method, where the character is moved based on a 3D model or simple 3D primitives, and the other is the 2D-based method, where movement is shown by changing the structure of the image while keeping it in 2D.
An easy-to-understand 3D-based method is to create a 3D model from standing pictures of characters. However, there are other methods that change images based on 3D information. For example, there is a method that approximates the movements of each part to a simple 3D model and morphs or switches shapes of the parts [Rivers2010].
On the other hand, a famous application of the 2D-based method is Live2D. Interpolating shape changes by meshing the image is a representative research theme in the fields of image processing and computer graphics.
The method introduced in this article is classified as a 2D-based method. This method learns changes and interpolation based on a large number of 2D images of character faces.
In this technology, to control the facial expressions and head orientations of a single front-facing character image, the parts and rotation angles are expressed as parameters, and inference is performed using these parameters and the front-facing character image.
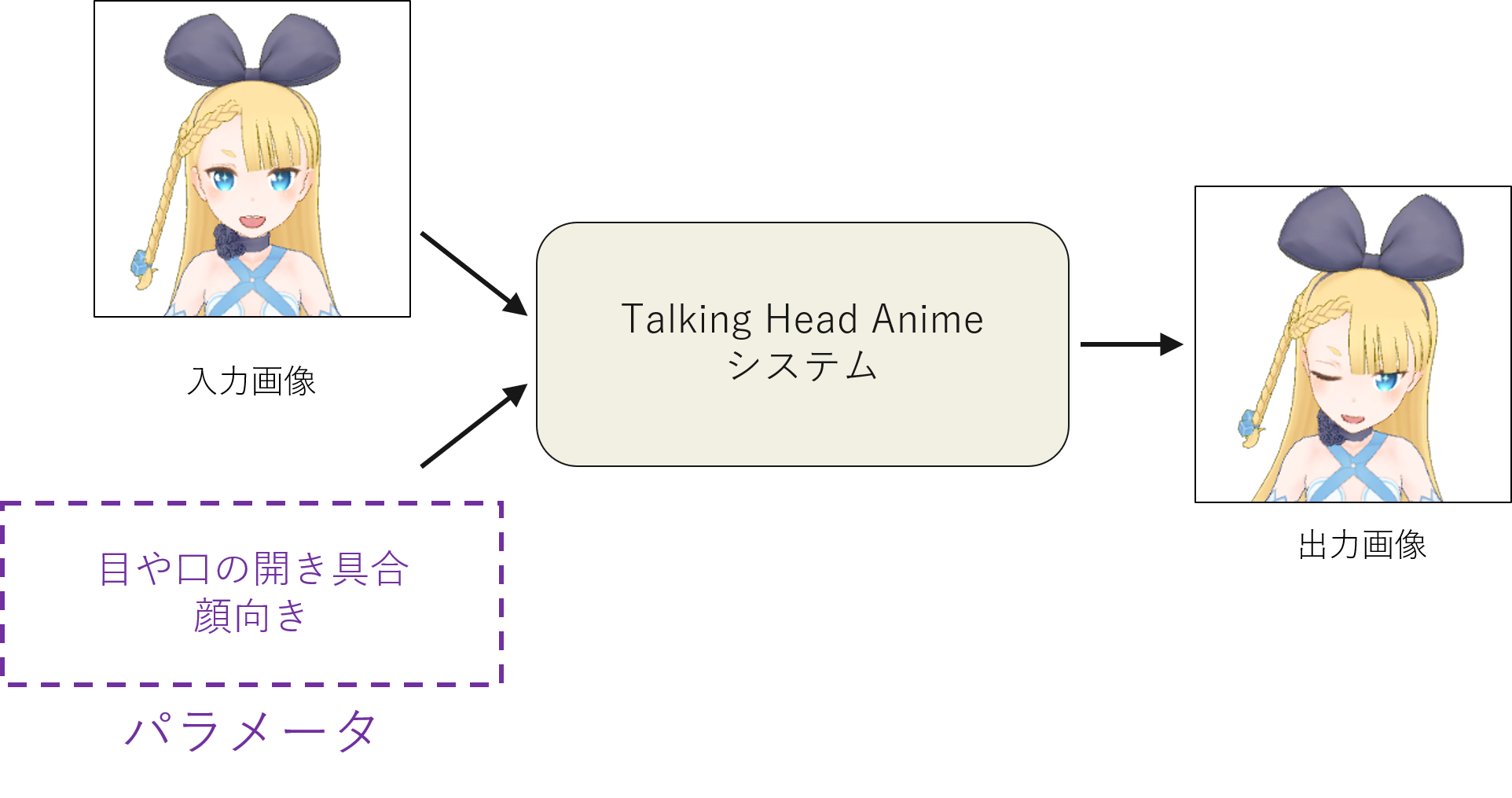
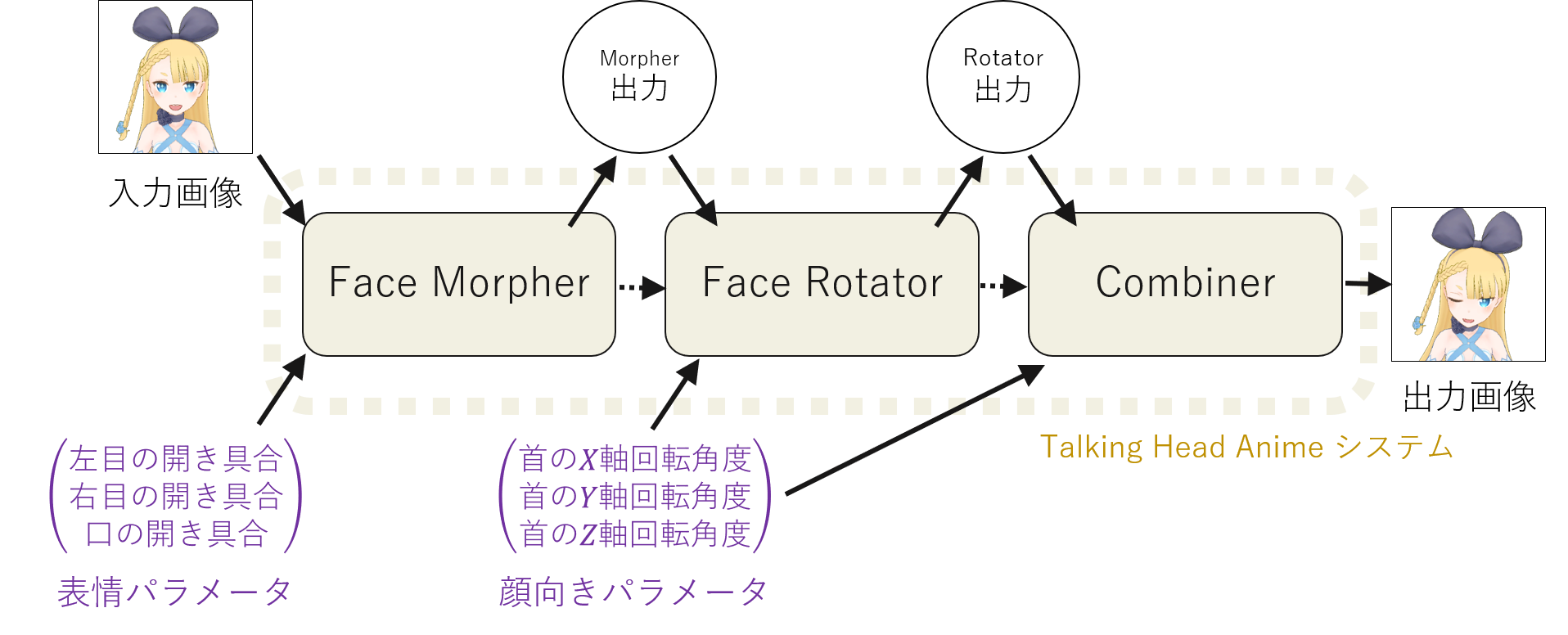
In Khungurn’s implementation, to control the expressions, the parameters are trained to control the opening and closing of the left eye, right eye, and mouth, and the rotations of the head on the X, Y, and Z axes. In this reproduction, I also adopted the same 3D parameters for each. The next section describes the range of parameter values and what can be controlled. In Khungurn’s implementation, the parameters for expressions were associated with values ranging from 0 to 1, representing fully open to fully closed states for each face part. The rotation angle range was set to allow face orientation changes of -15° to +15°, with these rotation angles associated with parameters ranging from -1 to +1. Similarly, in this reproduction, expressions were represented by values ranging from -1 to +1 for fully open eyes and mouth, and rotations by values ranging from -15° to +15° for each axis, ranging from -1 to +1. The reason for limiting the rotation angle range to -15° to +15° is that, compared to changes in expressions, predicting the trajectory of part movements becomes difficult with larger rotation angles due to factors like occlusion caused by 3D rotations. Therefore, I aimed to test if the expression could be sufficiently achieved within this rotation angle range, similar to Khungurn’s implementation.
Three networks are used in total. The reproduction also adopted the same network structure. The networks are the Face Morpher Network for achieving expression changes, the Face Rotator Network for achieving head orientation changes, and the Combiner Network for final adjustments. The front-facing character image is input into the Face Morpher Network to achieve expression changes, then the output of the Face Morpher Network is input into the Face Rotator Network to achieve head orientation changes with expression changes. Finally, the output of the Face Rotator Network is finely adjusted by the Combiner Network, resulting in the final face image with expression and head orientation changes. In other words, to obtain the final image, there are three generation stages, and each stage has one network and three-dimensional parameters.
The Face Morpher Network is based on an encoder-decoder network and masks the expression change area in the original image at the final part.
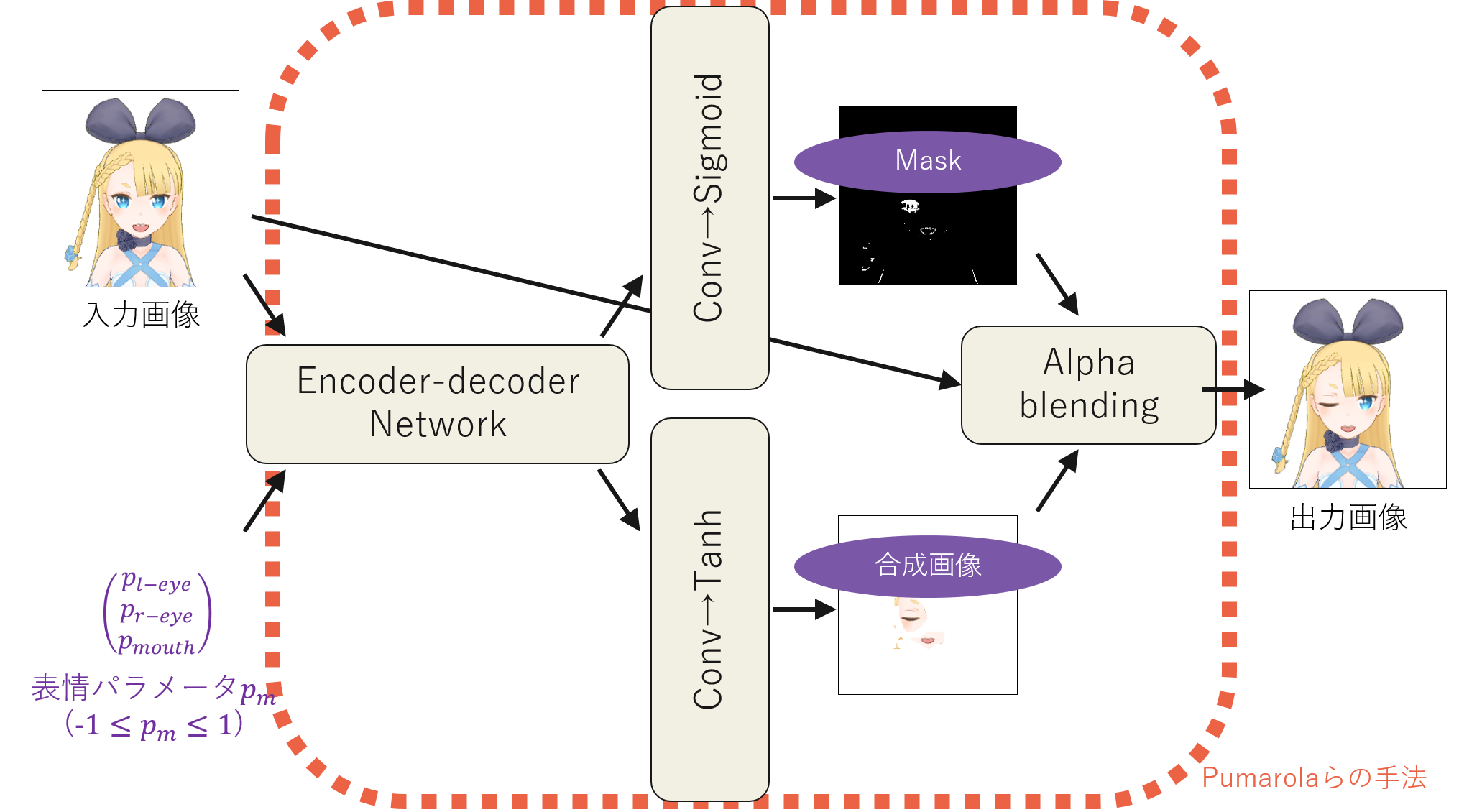
The output with the Sigmoid function applied is the mask, and the output with the Tanh function applied is the expression change part to be combined using the mask. This structure is based on the method by Pumarola et al.
The Face Rotator Network has two outputs.
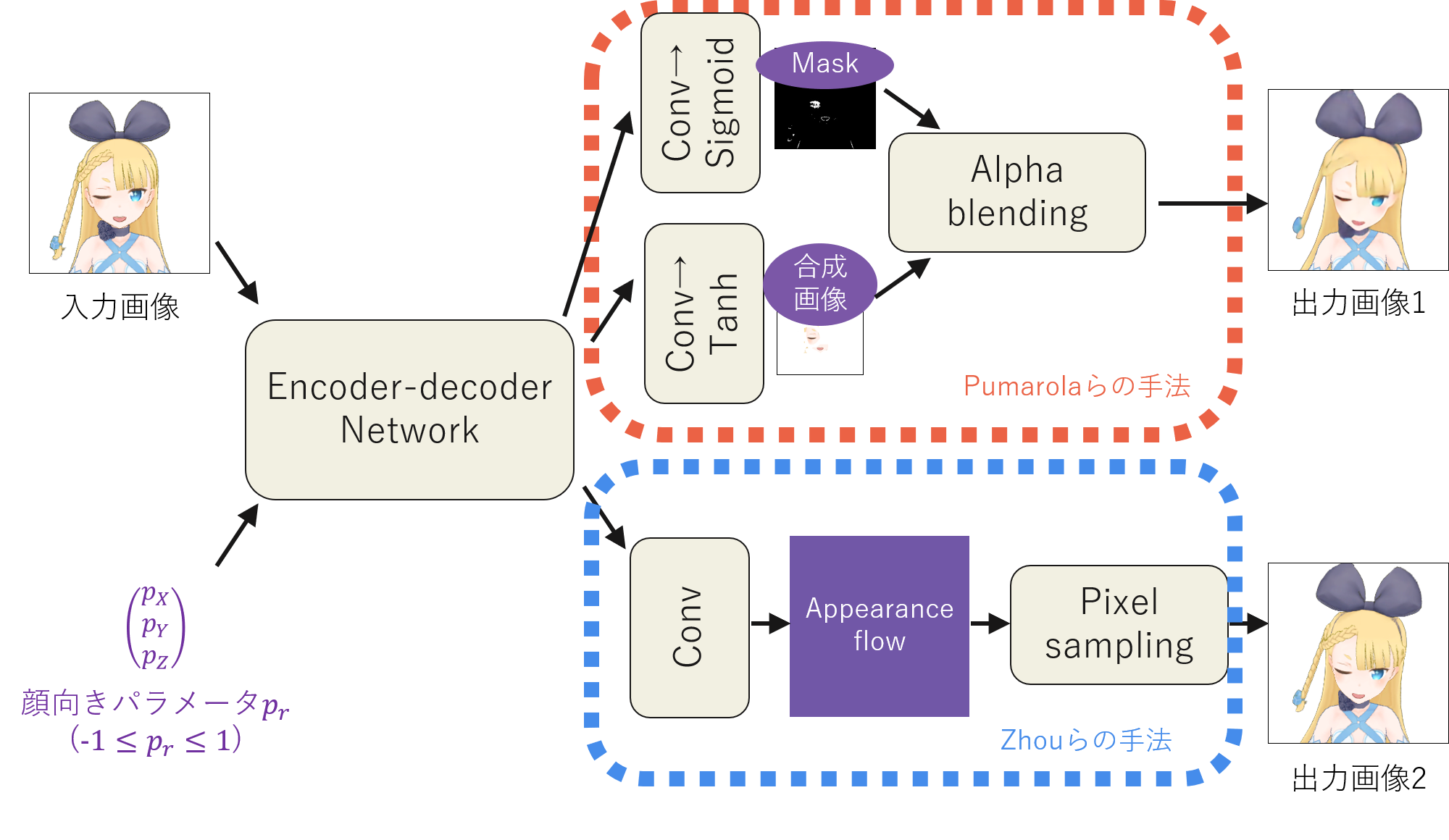
The first output is from the process outlined in orange dashed lines in the figure. This adopts the same method by Pumarola et al., combining the change part using a mask. The new addition in the Face Rotator Network is the process outlined in blue dashed lines in the figure. This is based on the method by [Zhou2016], using a composition method called Appearance Flow, which is a map of pixel movements.
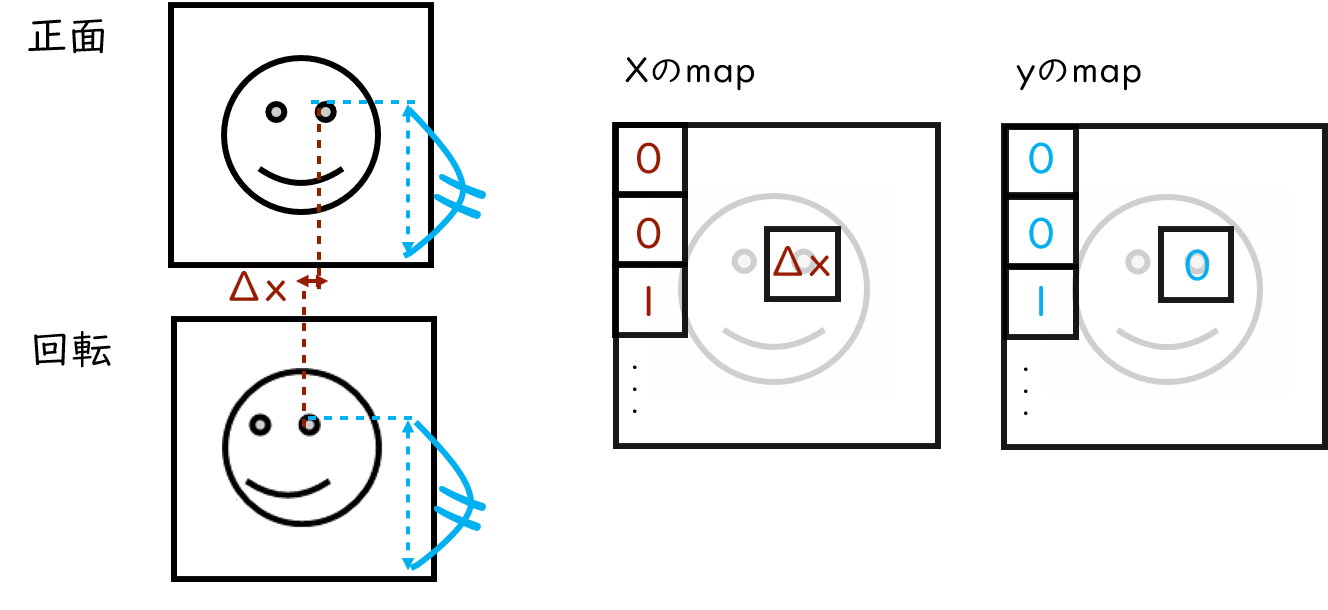
When 3D rotation causes image changes projected on a 2D plane, it can be interpreted as “a pixel moved to another place.” This concept is the basis of Appearance Flow. In the example above, when rotating from the front, the coordinate of the left eye changes by Δx in the X-axis and 0 in the y-axis. This movement is recorded in the map. The Appearance Flow is a map that expresses how many pixels each coordinate moves along the X and Y axes during rotation. The result composed along this map is the second output of the Face Rotator Network.
Finally, the Combiner Network combines the two outputs from the Face Rotator Network. The target for the output image is an image with both expression and rotation changes, the same as the Face Rotator Network. The parameters are also the same three-dimensional parameters related to the rotation angles for each axis as in the Face Rotator Network.
Here, consider why two outputs from the Face Rotator Network were necessary. You might wonder if the output using only the method by Pumarola et al., like in the Face Morpher Network, would have sufficed. However, in practice, the results from the method by Pumarola et al. showed blurred faces and unclear fine lines of hair, indicating a loss of high-frequency components. On the other hand, the output using the method by Zhou et al., added as the second in the Face Rotator Network, showed artifacts near regions occluded by face orientation changes but retained clear high-frequency components. Therefore, the Combiner Network incorporated the strengths of both methods.

In the figure above, the high-frequency components like the eyes within the green frame are blurred in (a) and clear in (b), and the combined output in (c) shows a high-resolution expression. The region within the red frame, where occlusion occurs due to face rotation, is appropriately represented in (a), while artifacts appear in (b), and the combined final output in (c) is closer to the correct representation as in (a). In summary, the high-precision expression that could not be achieved with Pumarola’s method alone was supplemented by Zhou’s method, which can be succinctly described as ‘reusing pixels,’ resulting in better expression.
The dataset uses a large number of
character images. However, the data consists of images taken from 3D models. The front-facing character image input to the initial Face Morpher Network is an image with fully open eyes and mouth. Khungurn’s method refers to this as the Reset Image.
In addition to fully open eyes and mouth, the Reset Image has another condition. The top of the head to the tip of the chin must be centered in the image and occupy half the image.

2D characters are represented with various colors, shapes, and lines, with varying positions and sizes of parts. To ensure consistent quality of expression and head orientation changes for such varied character images, precise alignment is necessary during dataset creation. Specifically, the top of the head to the tip of the chin must occupy half the image and be centered. This precise alignment required manually marking the top of the head and the tip of the chin for all characters to gather Reset Images. Khungurn’s implementation also performs this precise alignment.
For each character, three types of images are required: the Reset Image, an image with expression changes only (correct for the Face Morpher Network), and an image with both expression and head orientation changes (correct for the Face Rotator Network and Combiner Network). Khungurn’s implementation used the following numbers of images as the training dataset. The number of validation and test dataset images is also disclosed in Khungurn’s article section 5.4.
| Khungurn’s Training Set | Number |
|---|---|
| Number of characters | 7,881 |
| Number of expression and head orientation combinations | 500,000 |
| Number of Reset Images | 7,881 |
| Number of images with expression changes only (Morpher correct) | 500,000 |
| Number of images with expression and head orientation changes | 500,000 |
| Total number of images | 1,007,881 |
The 3D character models used for the reproduction dataset were collected from Nico Nico 3D. Due to differences in joint tree structures, the number of joints, parameters for facial expression control, shaders, etc., for each character model, there were many manual processes involved in dataset creation. It was also challenging to find a sufficient number of models available for use in the dataset. Therefore, the reproduction dataset consists of a relatively small number of characters, 357, but with increased shooting numbers per character. The number of images in the reproduction dataset is as follows.
| Reproduction Training Set | Number |
|---|---|
| Number of characters | 357 |
| Number of expression and head orientation combinations | 714,000 |
| Number of Reset Images | 357 |
| Number of images with expression changes only (Morpher correct) | 714,000 |
| Number of images with expression and head orientation changes | 714,000 |
| Total number of images | 1,428,357 |
Despite the smaller number of characters compared to the original technology, the results of the demo and examples suggest that the reproduction was sufficiently generalizable. A different point in the dataset used in this reproduction from Khungurn’s dataset is the lighting environment during rendering. Khungurn’s method used only the Phong model for lighting during image collection, aiming to use data close to hand-drawn images by reducing noise from various lighting models. However, the reproduction dataset used point light sources and shaders set for each character during image collection. Despite the potential for non-convergence in learning, the reproduction showed similar shadow expression results to Khungurn’s implementation. Below is a comparison when a front-facing character image with shadows cast by bangs was input.
| Reset Image |  |  |  |  |
|---|---|---|---|---|
| Khungurnの実装 |  |  |  |  |
| 古澤の実装 |  |  |  |  |
In Khungurn’s implementation, the image size for both input and output images is 256px. For the reproduction, I experimented with obtaining 512px images by passing the output of the Talking Head Anime model through a super-resolution model.
While super-resolution processing caused some noticeable artifacts, increasing the output size seemed to improve the sense of resolution. The demo released this time keeps the output size at 256px due to processing time and data load considerations for users, but applying super-resolution processing could be beneficial depending on the application.
In recent years, with the rise of virtual YouTubers, there seems to be a growing demand for technology that allows anyone to easily animate characters. However, creating 3D models as desired is a specialized skill, and acquiring the knowledge is not easy. Against this backdrop, the technology introduced in this article is fascinating, as it allows even those who can only draw sketches to animate their characters.
Furthermore, even those who cannot draw sketches can generate their favorite characters or create characters by mixing their favorite ones using recent image processing and deep learning technologies. This means that in an era where it is becoming unnecessary even to draw pictures to animate your favorite characters, this technology has many potential applications. It is exciting to think about what new research and entertainment will emerge when the technology of “anyone can create and animate characters” becomes widely adopted.
[Khugurn] Pramook Khungurn, 'Talking Head Anime from a Single Image', 紹介記事 https://pkhungurn.github.io/talking-head-anime/
[Rivers2010] Alec Rivers, Takeo Igarashi, Frédo Durand, '2.5D cartoon models', ACM Transactions on Graphics, July 2010 Article No.59 https://doi.org/10.1145/1778765.1778796
[Igarashi2005] Takeo Igarashi, Tomer Moscovich, John Forbes Hughes, 'As-Rigid-As-Possible Shape Manipulation', SIGGRAPH '05 ACM SIGGRAPH 2005 Papers, July 2005 Pages 1134–1141 https://dl.acm.org/doi/10.1145/1186822.1073323
[Pumarola2019] Albert Pumarola, Antonio Agudo, Aleix M. Martinez, Alberto Sanfeliu, Francesc Moreno-Noguer, 'GANimation: Anatomically-aware Facial Animation from a Single Image', International Journal of Computer Vision (IJCV), 2019 https://arxiv.org/abs/1807.09251
[Zhou2016] Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, Alexei A. Efros, 'View Synthesis by Appearance Flow', European Conference on Computer Vision (ECCV), 2016 https://arxiv.org/abs/1605.03557

Chie Furusawa