This article is automatically translated.
| Input Voice | Target Voice | Conversion by Existing Method | Conversion by Proposed Method |
|---|---|---|---|
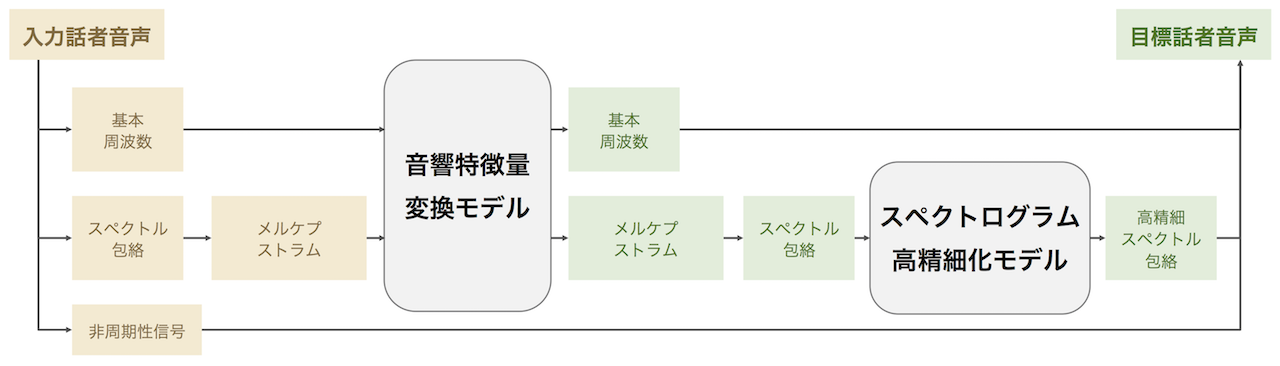
In this research, we propose a method for high-quality voice conversion by dividing it into two models: a voice conversion model that can be trained with a small amount of parallel data, and a high-resolution model that can be trained with a large amount of non-parallel data. In the first-stage model, we use a convolutional neural network (CNN) with a one-dimensional convolutional layer in the time direction to convert the fundamental frequency and lower-order Mel-cepstrum series of the input speaker to those of the target speaker while considering temporal dependencies. In the second-stage model, we use a GAN to enhance the excessively smoothed acoustic features during conversion. Experimental results show that the proposed method can achieve voice conversion with the same naturalness and higher individuality compared to conventional methods.
We compared the naturalness and individuality of the converted voices through a subjective evaluation experiment. Naturalness indicates how natural the voice sounds, and individuality indicates how much the voice sounds like the target speaker. The naturalness of the converted voices was evaluated by an AB test. Voices converted by conventional and proposed methods were played in random order, and subjects selected the voice with higher naturalness. The individuality of the converted voices was evaluated by an XAB test. After playing the target voice, voices converted by conventional and proposed methods were played in random order, and subjects selected the voice that was similar to the target voice. Nine subjects evaluated 15 pairs of voices. The conventional method used the difference spectrum method with GMM sprocket [2]. The conventional method model was trained with 50 parallel data sentences. The proposed method used two models with different numbers of training data for the high-resolution model.
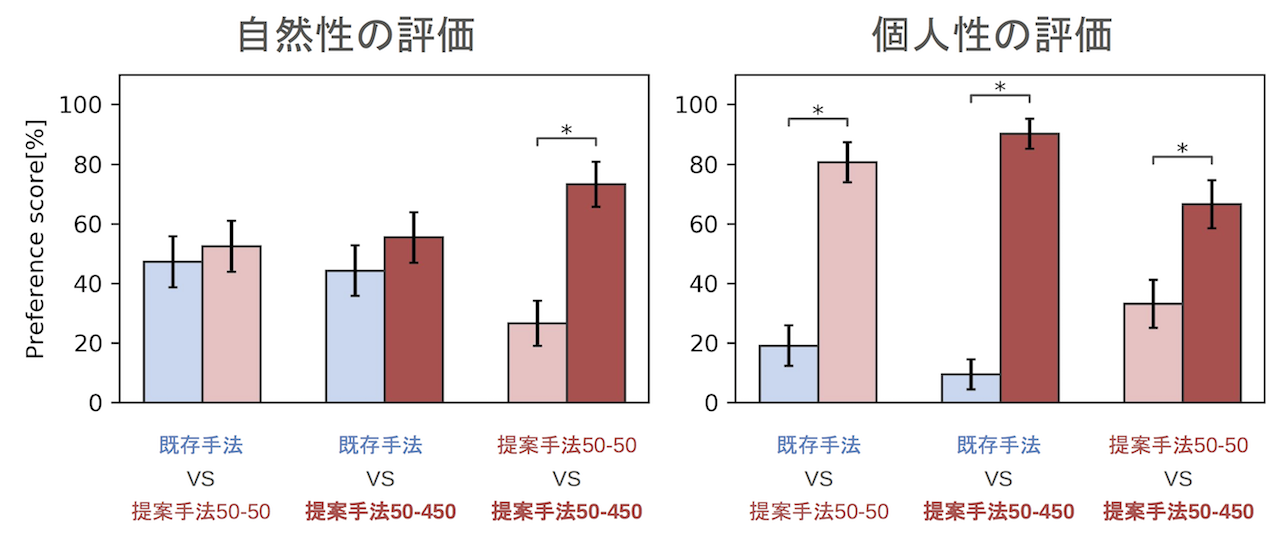

The converted voices of the proposed method were found to have the same naturalness and higher individuality compared to the conventional method. By increasing the number of target speaker’s voice data used for training, more natural and individual conversion voices were obtained.
With permission for publication, we also include sample voices trained with the new Voice Actor Statistical Corpus [3]. The input voice was the author’s (male in his 20s). Using the proposed method, we converted the author’s recorded voice to a professional female voice using the Voice Actor Statistical Corpus as training data. For comparison, we also present the conversion results using sprocket. Out of 100 sentences in the Voice Actor Statistical Corpus, 95 parallel data sentences were used for training, and the remaining 5 sentences were used as test data. The target voices were audio data resampled at 16000Hz from tsuchiya_normal_001.wav to tsuchiya_normal_005.wav in the Voice Actor Statistical Corpus. Unlike the 450-sentence experiment in the paper, the Voice Actor Statistical Corpus had 100 sentences, so there may not be a clear difference from the existing method.
For the proposed method, it is possible to improve the quality of conversion results by increasing the non-parallel data of the target speaker.
| Input Voice | Target Voice | Conversion by Existing Method | Conversion by Proposed Method |
|---|---|---|---|
[*] The copyright of the paper belongs to the Information Processing Society of Japan
[1] Morise, M., Yokomori, F. and Ozawa, K., WORLD: a vocoder-based high-quality speech synthesis system for real-time applications, IEICE T INF, 2016. https://github.com/mmorise/World
[2] K. Kobayashi, T. Toda, sprocket: Open-Source Voice Conversion Software, Proc. Odyssey, 2018. https://github.com/k2kobayashi/sprocket
[3] y_benjo and MagnesiumRibbon, 声優統計コーパス, 2017. https://voice-statistics.github.io/