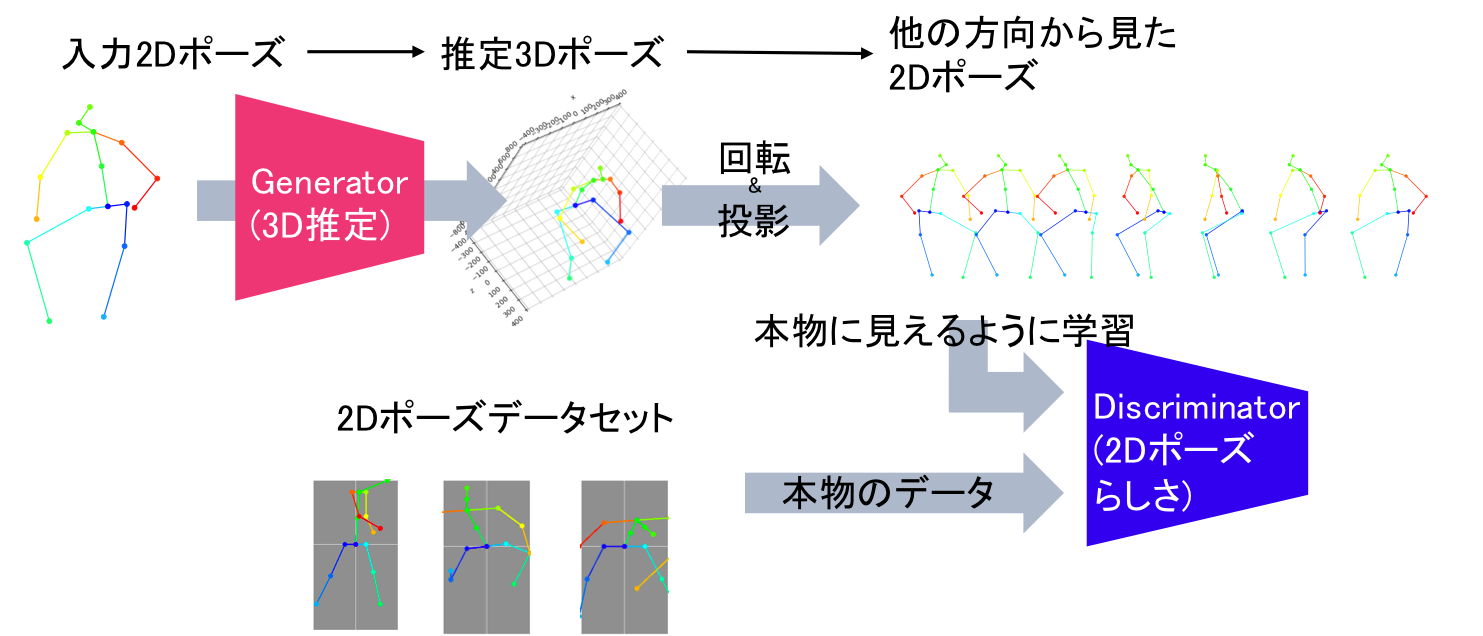
The task of three-dimensional (3D) human pose estimation from a single image can be divided into two parts: (1) Two-dimensional (2D) human joint detection from the image and (2) estimating a 3D pose from the 2D joints. Herein, we focus on the second part, i.e., a 3D pose estimation from 2D joint locations. The problem with existing methods is that they require either (1) a 3D pose dataset or (2) 2D joint locations in consecutive frames taken from a video sequence. We aim to solve these problems. For the first time, we propose a method that learns a 3D human pose without any 3D datasets. Our method can predict a 3D pose from 2D joint locations in a single image. Our system is based on the generative adversarial networks, and the networks are trained in an unsupervised manner. Our primary idea is that, if the network can predict a 3D human pose correctly, the 3D pose that is projected onto a 2D plane should not collapse even if it is rotated perpendicularly. We evaluated the performance of our method using Human3.6M and the MPII dataset and showed that our network can predict a 3D pose well even if the 3D dataset is not available during training.
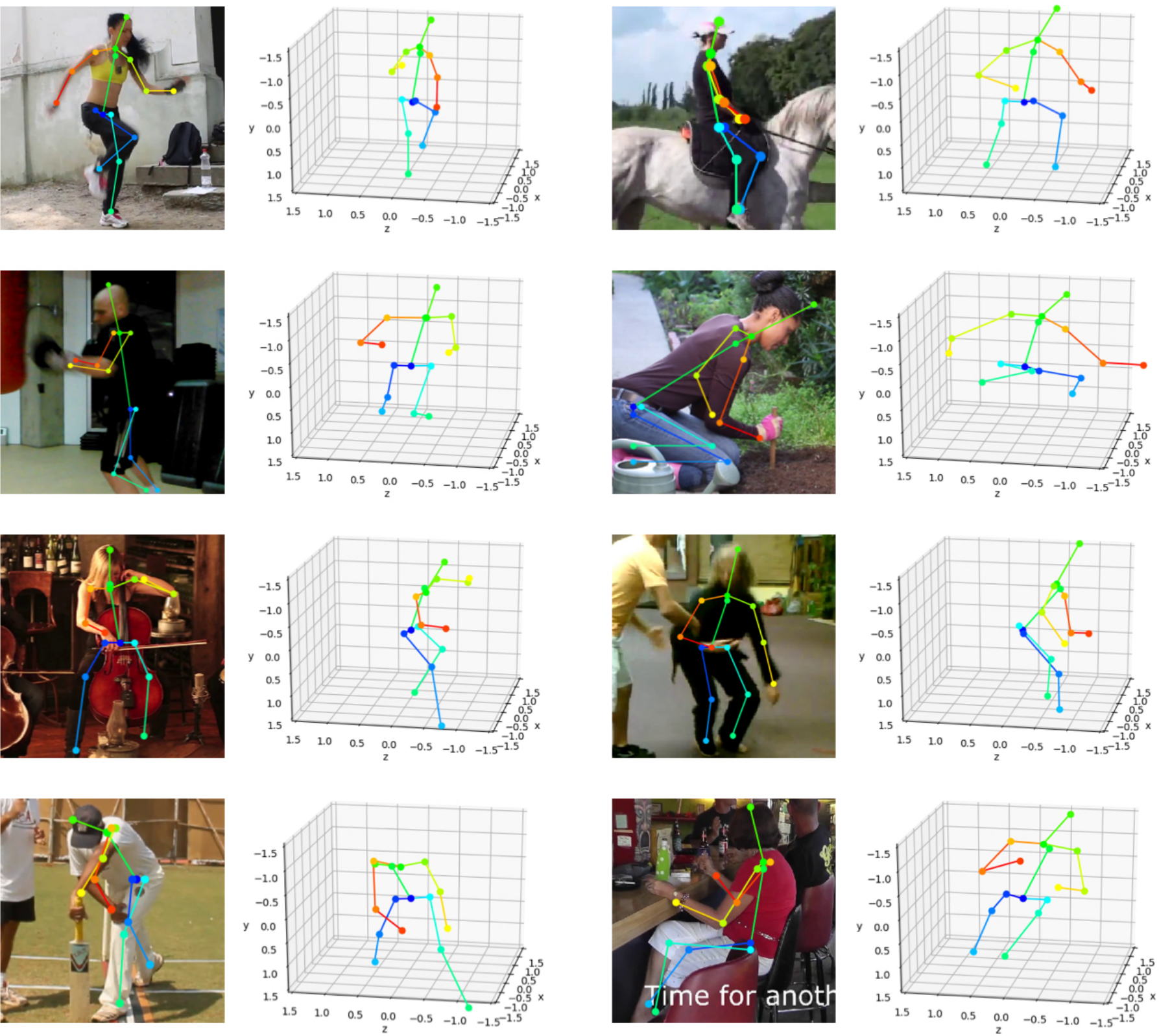
3D poses lifted from 2D poses from [MPII Human Pose Dataset]. Note that we trained our model using only 2D poses in the dataset. 2D poses shown in the images are ground-truth annotations in the dataset.
Frame-by-frame 3D pose estimation for videos. We first applied the openpose [Cao2017] to extract 2d poses, then lift 2d poses to 3d poses using our method.
@misc{kudo2018,
Author = {Yasunori Kudo and Keisuke Ogaki and Yusuke Matsui and Yuri Odagiri},
Title = {Unsupervised Adversarial Learning of 3D Human Pose from 2D Joint Locations},
Year = {2018},
Eprint = {arXiv:1803.08244},
}
[Cao2017] Cao, Z., Simon, T., Wei, S.E., Sheikh, Y.: Realtime multi-person 2d pose estimation using part affinity fields. In: CVPR. (2017) https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation
[Goodfellow2014] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative Adversarial Nets. In: NIPS. (2014) https://papers.nips.cc/paper/5423-generative-adversarial-nets
[Martinez2017] Martinez, J., Hossain, R., Romero, J., Little, J.J.: A simple yet effective baseline for 3d human pose estimation. In: ICCV. (2017) https://arxiv.org/abs/1705.03098