
Dwango Media Villageの古澤です。 この記事では、棒人間を描くことで、3Dキャラクタモデルのポーズを指定するデモとその手法について紹介します。 よろしければ、まずは下のデモを使ってみてください。 ポーズの指定には、手描きスケッチの検索と機械学習を用いた静止画からの3Dポーズ推定の手法が絡んでいます。 手法詳細を先に読まれたい方は、先にお進みください。

3つ表示される候補ポーズのうち、左端のポーズが反映されます。(第2,3候補は表示のみで選択はできません。)
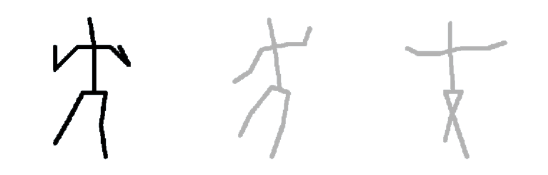
右側のキャンバスに棒人間を描くと、スケッチした棒人間に最も近いポーズをキャラクタがとります。 左上に表示されている3枚の棒人間は、左から近いとされたポーズ(棒人間画像)です。 その他に、背景を変更するボタンもあるので、その景色になじむポーズの画像を作成できます。
| UI | 説明 |
|---|---|

|
スケッチをリセットします。 |

|
キャラクタの二人目を追加できます。再度押すと、一人目だけになります。ポーズの更新の対象は最後に追加されたキャラクタです。 |

|
描いたスケッチを表示/非表示します。 |

|
背景画像を入れます。クリックすると背景が変わります。 |
|
スケッチから推定された候補のポーズです。左が最も近いと推定され、キャラクタがとるポーズです。左から順に似ていると推定されたポーズです。 |
スケッチ位置と大きさにキャラクタが追従する様子や、1ストロークごとにポーズが変わる様子などを体感していただけると思います。
背景に合わせたこのような画像を作成できます。



画像やキャラクタモデルなどは以下のサイト様のものを利用させていただきました。ありがとうございました。
3Dキャラクタモデルのポーズを操作できれば、色々なキャラクタをインタラクションの要とするアプリケーションに応用できます。 3Dキャラクタモデルのポーズは、そのモデルの関節に関する情報を指定することで、操作できます。 モーションキャプチャやキネクトなどは、3D関節情報を得る技術の代表例といえるでしょう。 しかし、私たちはモーションキャプチャなどの特別な機械を用いずに、もっと簡単な入力をもとに、キャラクタのポーズを指定することはできないか考えました。
「もっと簡単な入力」の一例として、モバイルやウェブカメラから得る全身画像があげられます [*]。 Dwango Media Villageでは、昨年、学習に3Dデータセットを用いない3D姿勢推定の研究を行いました [1]。 この研究を用いると、静止画から3D関節座標を得られます。 上のデモではこの研究を用いて手描きの棒人間から3D関節の座標を推定することで、キャラクタにポーズをとらせています。 これら例のように、スマートフォン内蔵カメラやウェブカメラなどの多くの人が持つデバイスから得られる静止画や、手描きの棒人間の画像など、 特別な機械を使わずに得られる入力から3Dキャラクタの関節座標を得られることは、 より多くの人が3Dキャラクタのポーズを指定する体験ができるようになる上で重要だと考えられます。
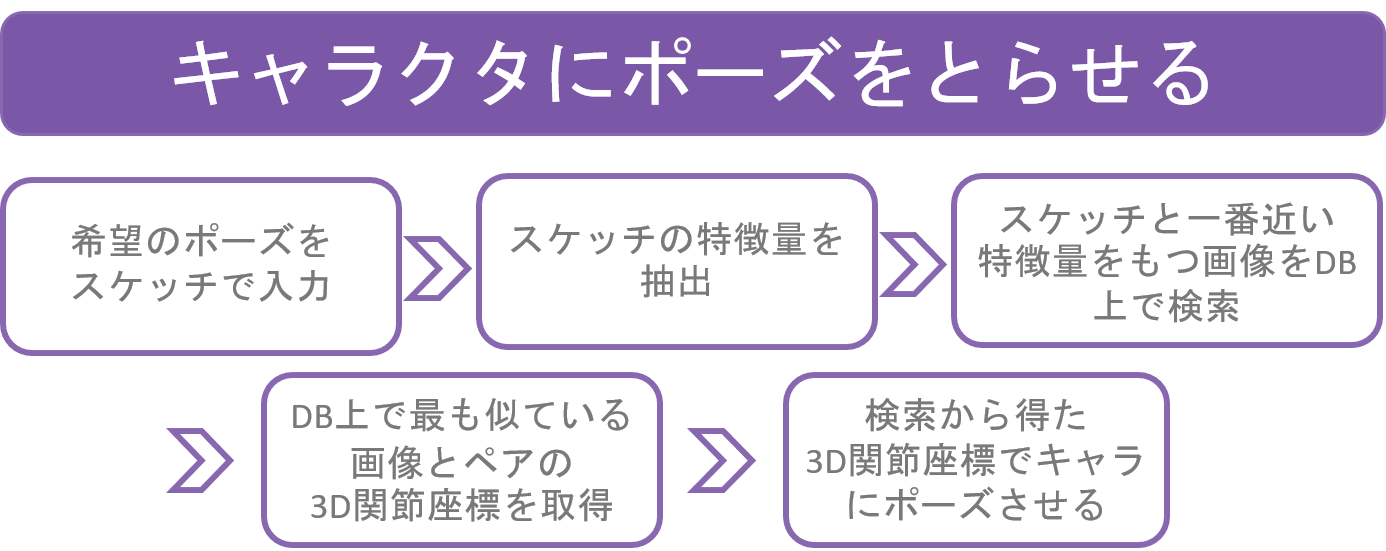
今回のデモは、手描き棒人間の画像を入力として、3Dの関節座標を推定しています。 描いた棒人間をもとに3Dキャラクタにポーズを指定する流れは、以下のようになっています。 今回のデモでは、棒人間から希望のポーズを当てるために、 データベース上にある3Dポーズと紐づけされた棒人間の画像と、手描きの棒人間の画像特徴量を比較することで、最も類似したポーズを見つける 方法を採用しています。
画像特徴量は、Sketch-based Manga RetrievalのFMEOHを用いました [2]。 この特徴量を用いて、データベースに置く“人工棒人間”画像の画像特徴量と、ユーザが描いた“手描き棒人間”画像の画像特徴量を算出します。
“人工棒人間”画像の生成と、その“人工棒人間”画像とペアになる3D関節座標の推定は、 [1]の3Dポーズ推定の研究を用いて、同じ全身画像から行われます。 まず、訓練済みモデルを用いて、全身画像から3Dポーズを推定します。 推定された3D関節座標をもとに各関節位置を描画した画像が“人工棒人間”画像です。 この画像を、推定結果の3D関節座標とペアになっているものが、今回の手法のデータべース上における、一つのデータなります。 3D関節座標を推定で得ているので、“人工棒人間”画像は任意の角度から見たポーズを“人工棒人間”画像として描画できるのですが、 今回は入力静止画と同じ角度から見たときの棒人間画像のみからデータを作りました。 デモで用いているポーズは、データベース上の約260個のデータから選ばれています。
このように、画像類似度を測る研究と、静止画から3Dポーズ推定を行う研究を組み合わせることで、一連の、 「棒人間をスケッチ→棒人間と近い3Dポーズを推定→推定結果の3Dポーズをキャラクタへ適用」という流れを実現しています。 検索を用いることで、ただスケッチの棒人間から3Dポーズを推定するよりも、破綻したポーズをとることを防いだり、3Dポーズの推定にかかる時間を削減できます。
前章の冒頭で、ポーズを指定するには3D関節情報を得る必要があると触れましたが、ここで、得た3D関節情報からどのように3Dキャラクタの関節を制御するのか、簡単に触れておきます。 3D関節の3D座標を指定することで姿勢を決定する方法を逆運動学(IK)といいます。 一方で、関節角度を指定することで姿勢を決定することを順運動学(FK)といいます。 今回は、推定された3D関節座標を利用してポーズを指定したいので、 IKを用いた、関節位置のゴール位置を指定することでキャラクタの関節位置を指定位置に動かすことのできるパッケージやライブラリを用いることにしました。 その一つとして、UnityのパッケージであるFinal IKがあります。 今回は、このFInal IKを使って、キャラクタのポーズを指定しています。
最後に、今回なぜこのような応用先を考えたかを少し触れたいと思います。 近頃、静止画から推定された3D関節座標を応用した様々なアプリなどが次々に出てきています [3], [4]。 エンターテイメントへの応用先として全身画像を入力とすることは、「ひとりで発信できるコンテンツ」への応用を目指す面で的確なのか筆者は疑問に感じていました。 スマートフォンなどで自分で自分の全身を自撮りすることは、難しいからです。 その問題を解決策の一つとして、入力を上半身のみ、顔のみの画像を入力とするものもあります。 しかし、筆者は、キャラクタの全身ポーズを指定してみたいという思いがあったため、自撮りの全身画像を入力として必要としない、キャラクタを動かす方法を考えた結果、今回の開発に至りました。 これから、静止画から推定された3D関節座標を用いる誰も想像していなかった様々なアプリやコンテンツが出てくることも期待できるかもしれません。 そのことを楽しみにすると同時に、この分野の発展に貢献できる人間の一端になれればと思っています。
[3]HomeCourt - The Basketball App
[*] Androidだけでもアリシアちゃんになれちゃうアプリを作った話@第45回コンピュータビジョン勉強会

Chie FURUSAWA