Dwango Media Villageの佐々木です。 最近使い始めた強化学習のフレームワークRLlibの紹介をしたいと思います。
深層強化学習は最近着目を浴びている機械学習技術の1つで、盛んに研究がされています。 大量のサンプルデータを必要とする教師あり学習とは異なり、強化学習は環境とエージェントのインタラクションから得られる経験データを必要とします。 そのため、いかに効率的にインタラクションの経験データを集めるかが重要になります。 プロセス・ノード間で経験データの収集プロセスを並列化することで収集効率を上げることができますが、実装如何で性能が大きく変わってしまいます。 さらに学習法や探索法も日々新しい手法が提案される中、ゼロから最新の学習法をサポートする実験プログラムを実装するのは大変な作業です。
そこで実験のためのフレームワークとしてRLlib[Liang et al., 2018]を使ってみることにしました。 収束が早いQ学習のアルゴリズムApe-X[Horgan et al., 2018] をはじめとして代表的な手法が実装されています。 GitHubのスター数が多い、つまり多くのひとが使っていそうというのも理由の1つです。
RLlibは便利ですが、様々なアルゴリズムをサポートしているために設定項目が多く、ドキュメントの説明も簡素なものしかありません。 そこで、この記事ではApe-Xを例にしてRLlibの学習設定項目を説明していきたいと思います。 はじめに導入として、Ape-X, RLlibの概要をおさらいします。 そしてRLlibの簡単な使い方として学習の始め方を説明します。 最後に学習を行う際の設定項目をApe-Xに関連するものを中心に説明していきます。
Ape-Xは論文Distributed Prioritized Experience Replay[Horgan et al., 2018]で提案されたDQNの1種です。
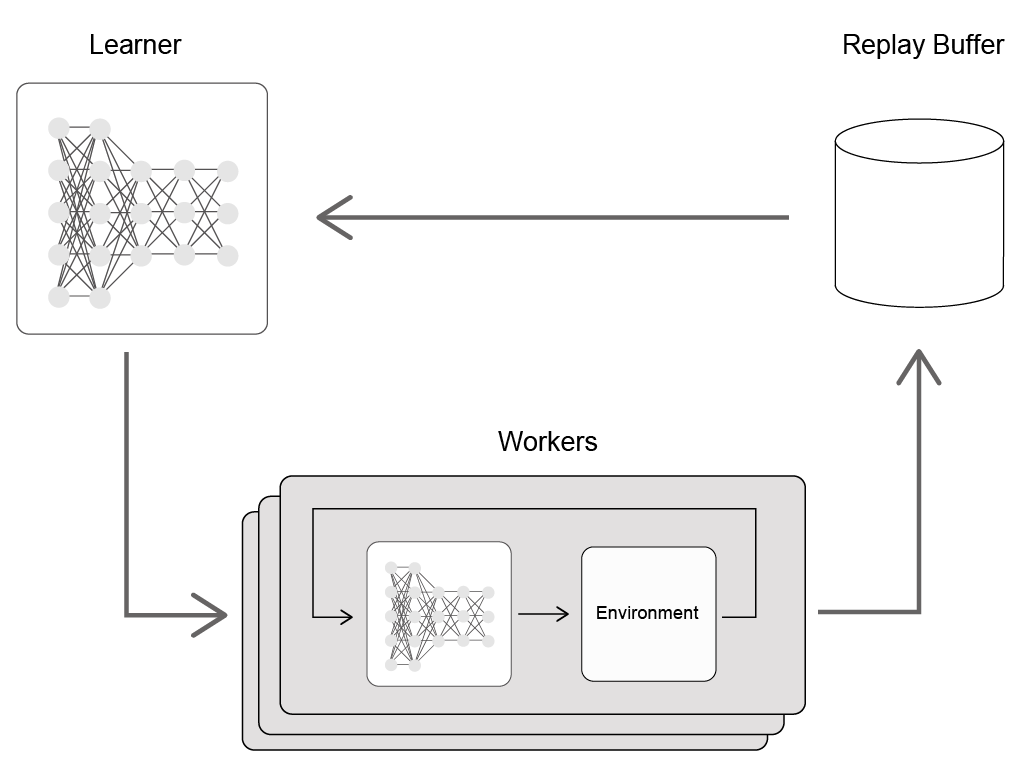
Ape-Xは過去に提案されたDQNの性能を向上させる方法を組み合わせ、分散学習を導入したものです。 多数の探索を行うWorkerを並列に実行し、得られた経験データをReplay Bufferに貯め、そしてQ-Networkのパラメーター更新はGPUを使って一括で行います。 このときの勾配計算に使われるバッチ入力をReplay BufferからTD誤差にもとづく優先度を使って選びます。 より具体的には以下の3つの方法が導入されています:
RLlibはPythonの分散実行ライブラリRayの1つのサブパッケージであり、学習実験を行う際にはRayに加えて他のサブパッケージTuneと組み合わせて使えるようになっています。
Rayはプロセス・ノード間で共有可能なimmutableオブジェクトを介して実行される関数を非同期で実行するためのライブラリです。
Ray特有のデコレートされたPythonの関数fooを定義するとfoo.remote()が呼べるようになります。そしてfoo.remote()を実行すると関数が実行されますが、オブジェクトの値そのものは即座に評価されずに計算の実行がスケジューラーに予約されます。
関数が返すのは共有用のオブジェクトの固有IDです。
このIDをray.get()に渡すと計算が実行されます。
複数の計算過程を実際に実行するためのスケジューラーはray.init()で開始することができます。
RLlibで学習を行うということはスケジューラーに計算を予約することに相当します。
サーバーは毎回新たに立ち上げるか、すでに走っているサーバーにネットワークを通して計算の実行を登録することも可能です。
Tuneはハイパーパラメータの推定や学習実験を遂行・可視化するためのライブラリです。
パラメーター探索のために学習実験を複数回、メタな推論アルゴリズムなどを組み合わせて行うための機能が実装されています。
学習実験をExperimentという単位で管理しており、キューとして複数の実験を溜め込み、順番に実行します。
今回はRLLibの学習サンプルスクリプトのように1回の強化学習実験のみを行うことを想定します。
学習実験を行うためには実験の内容を記述した辞書をray.tune.tune.run_experiments()に渡すだけです。辞書の内容は以下の通りです:
~/ray_results
runはA3C, IMPALAなどのアルゴリズムの名前を指定する必要があります。
詳細はRllibのページを参照してください。
強化学習の場合には名前に対応したAgentクラスが初期化され、メイン関数である_train()が複数回数呼び出されます。
Ape-XはRLlibではDQNの特別な場合として実装されています。APEXAgentはDQNAgentをオーバーライドしたクラスであり、主なパラメーターの説明はrayのソースにデフォルト設定と共に書いてあります。
デフォルト以外の設定を行いたい場合には上記のExperimentの設定configに辞書を追加すれば上書きされます。
また、configのおすすめ設定が結果付きで公開されています。
学習をカスタマイズしたい場合にはconfigを書き換える必要があります。 以下はその項目の説明です。
項目が多いのでカテゴリに分けて説明します。 カテゴリは実装と対応していないので注意してください。
Workerは分散で探索を行うプロセスを意味します。
学習を実行するマシンのリソース(CPU, GPU)に応じて設定する必要があります。
並列して実行するWorkerの数はnum_workers x num_envs_per_workerになります。
| 名前 | 型 | 説明 |
|---|---|---|
| num_workers | int | workerの数 |
| num_cpus_per_worker | int | 1つのworkerあたりに割り当てるCPUの数 |
| num_gpus_per_worker | int | 1つのworkerあたりに割り当てるGPUの数 |
| num_envs_per_worker | int | 1つのworkerあたりに割り当てる環境の数 |
APE-XではWorkerがε-greedyアルゴリズムを使って環境とインタラクション(Rollout)して経験データを生成します。
εの値は1.0からexploration_final_epsへと学習が進むにつれて変更され、変更はschedule_max_timestepsステップごとにexploration_fractionの割合だけ変更されます。
つまり、新しい$\epsilon$の値、$\epsilon_{i+1}$は以下のように決まります:
$$\epsilon_{i+1} = \epsilon_{i} + (\epsilon_{final} - \epsilon_{0}) $$
$\epsilon_{final}$, $\epsilon_{0}$はそれぞれexploration_final_eps、$\epsilon$の初期値(=1.0)です。
| 名前 | 型 | 説明 |
|---|---|---|
| per_worker_exploration | bool | workerごとにε-greedyのεの値を変えるか否か |
| exploration_fraction | float | εを減らす大きさ |
| horizon | int/null | Rolloutが特定のステップ数までが達したら強制的に止める |
| learning_starts | int | 何ステップRolloutしたら学習を開始するか |
| sample_async | bool | Rolloutを非同期に実行するか否か |
| sample_batch_size | int | 何ステップ分を1つのバッチとしてReplay bufferに送るか |
Prioritized Experience Replay[Schaul et al., 2016]はReplay BufferにQ学習にとってどのくらい役立つかの優先度をつけ、優先度が高いものを多く学習する手法です。 優先度の付け方は以下のアルゴリズムに従います:

9行目の$p_i$は優先度を決めるための確率で、TD誤差の絶対値に定数を加えたものです。
$$p_i=|\delta_i|+\epsilon$$
TD誤差のみで確率分布をつくると特定の経験のみが集中して使われ続けてしまいます。
そのため実際には分布$p_i$の調整を$\alpha, \beta$を使ってアニーリングしています。
特に$\beta$はprioritized_replay_betaからfinal_prioritized_replay_betaへと学習が進むにつれて$\epsilon$と同様に大きくなります。
| 名前 | 型 | 説明 |
|---|---|---|
| buffer_size | int | バッファ大きさ |
| prioritized_replay | bool | 優先度付き経験再生をするか否か |
| worker_side_prioritization | bool | WorkerがRolloutしたときに優先度づけを行うか |
| prioritized_replay_eps | float | TD誤差から優先度の確率分布を計算する際に加える定数 ε |
| prioritized_replay_alpha | float | TD誤差から優先度の確率分布を計算する際に加える定数 α |
| beta_annealing_fraction | float | βの変更幅 |
| prioritized_replay_beta | float | βの初期値 |
| final_prioritized_replay_beta | float | βの上限値 |
| compress_observations | bool | Replay Bufferに貯めるときに観測情報をLZ4で圧縮するか否か |
環境からのデータ処理についてはRayのページに概要が載っています。
Preprocessorは環境(Gym.Env)のラッパーとして働き、主に観測情報の事前処理を担当します。
環境がatariの場合には以下の4つが適用されます(
ただしcustom_preprocessorを指定した場合は除く)
env.reset()が呼ばれたタイミングとは異なり、ゲームオーバーになったときのみゲームプレイをリセットする| 名前 | 型 | 説明 |
|---|---|---|
| preprocessor_pref | string | 観測情報の前処理方法 |
| observation_filter | string | Preprocessorの後に行われる処理。デフォルトは何もしないNoFilterになる |
| synchronize_filters | bool | FilterのパラメーターをIterationごとに同期するか否か |
| clip_rewards | bool |
各ステップの報酬を[-1, 1]に抑えるかどうか。
trueの場合にはnumpy.sign()が使われる。
|
| compress_observations | bool | Replay Bufferに貯めるときに観測情報をLZ4で圧縮するか否か |
1 Iterationは以下のステップに相当します。checkpoint_freqはこのIterationが単位になっていることに注意してください。
timesteps_iteration分stepが経過するか、min_iter_time_s秒たつまでの間以下を繰り返す:
Replay Bufferへのデータ追加・リプレイは非同期で行われます。
| 名前 | 型 | 説明 |
|---|---|---|
| double_q | bool | Double Q-Learningを適用するか否か |
| dueling | bool | Dueling Networkを適用するか否か |
| gamma | float | 報酬の割引率 |
| n_step | int | n-step Q-Learningのnの値 |
| target_network_update_freq | int | 何ステップごとにQ-networkを更新するか |
| timesteps_per_iteration | int | Iterationのステップ間隔 |
| min_iter_time_s | int | 1 Iterationにかける最小の秒数 |
| train_batch_size | int | Q-Networkのバッチの大きさ |
Q-Networkの前向き計算・後ろ向き計算はTensorflowかPyTorchを使って行います。 Q-Networkの構成は自分で書くこともできますが、環境のもつobservation_spaceに合わせて自動的に構成を決めてくれます。 特に画像の場合にはCNNが適用され、Convolutionのカーネル大きさのみを設定で上書きすることも可能です。
| 名前 | 型 | 説明 |
|---|---|---|
| hiddens | int | Convolution層のあとのFully-Connectedな層の大きさ |
| noisy | bool | Noisy Network[Fortunato et al., 2017]を適用するか否か。これがtrueの場合にはε-greedyは使われない |
| sigma0 | float | Noisy Networkの初期パラメーター |
| num_atoms | int | Q-networkの出力分布の数。1より大きくするとdistributional Q-learning[Bellemare and Dabney, 2017]になる |
| v_min | float | distributional Q-learningのパラメーター |
| v_max | float | distributional Q-learningのパラメーター |
| 名前 | 型 | 説明 |
|---|---|---|
| optimizer_class | string | Optimizerの種類。Ape-Xの場合はAsyncReplayOptimizerを使う |
| debug | bool | デバックモードの切り替え |
| max_weight_sync_delay | int | モデルパラメーターの更新を前回行ってから何ステップ最低で待つか |
| num_replay_buffer_shards | int | Replayの並列数 |
| lr | float | 学習率 |
| adam_epsilon | float | Adam Optimizerのεの値 |
| grad_norm_clipping | float | 勾配のノルムの最大値 |
batch_modeはtruncate_episodes、complete_episodesのどちらかから選ぶことができます。 complete_episodesの場合はエピソードが終わるまでBufferに送りません。
| 名前 | 型 | 説明 |
|---|---|---|
| schedule_max_timesteps | int | ハイパーパラメータを学習の進み具合に応じて変える場合のステップ間隔幅 |
| gpu | bool | GPUを使うか |
| gpu_fraction | float | GPUの使用率(0~1, 1が100%) |
| monitor | bool | 定期的にRollout結果を動画で保存するか否か |
| batch_mode | string | Batchのサンプリング方法。 |
| tf_session_args | dict | TensorflowのSessionを初期化するときのパラメーター |
tf_session_argsは以下が設定することが可能です。詳しいことはTensorflowのドキュメントを参照してください。