こんにちは、DMV (Dwango Media Village) で長期インターンをしていた、芦田です。 普段は電気通信大学の3年次でセキュリティを学びながら、対外活動として VOICEVOX 歌声合成エンジンの研究開発に携わっています。
私は研究と開発の両方に関心があり、将来の就職にあたって、どちらかを選ばなければと考えていました。 その判断をするためにインターンを体験したいと考えていたところ、DMV という研究開発を一気通貫で行っている部署に出会いました。 そして、約2年ほどインターン生として迎えていただき、研究と開発のそれぞれに取り組む機会を得ました。 本稿では、取り組んだ順にそれぞれの内容を紹介します。
インターンを始めて最初に取り組んだのは開発タスクでした。 私のスキルセットと経験をチームの目標と照らし合わせてメンターである廣芝さんとも議論した結果、「社内向けのリアルタイム声変換デモアプリ開発」に取り組むことになりました。
ドワンゴが開発している生放送配信ソフトウェアである「N Air」には、DMV で研究開発されたリアルタイム声変換機能(ボイスチェンジャー)が搭載されています。 N Air は配信するためのアプリケーションなので、リアルタイム声変換を単体で利用できるようにはなっていません。 そこで、手軽に声変換機能を利用でき、配信以外の用途での応用を検討できるように、声変換機能だけを持つシンプルな社内向けのデモアプリの開発に着手しました。

シンプルながらUI/UXにも少しこだわり、主要な機能を1画面にまとめて、声変換を簡単に利用できるアプリを作りました。 これにより、初めて使う人でも使い方や現在の状態がわかりやすい形に仕上がりました。 他にも、仮想オーディオデバイスが同梱されており、アプリのインストール時に同時にインストールできるような工夫も行いました。 これにより、ボイスチャットなどで声変換を使うといったことがすぐに試せるようになりました。
技術スタックとしては、チームでの保守性を考えて、ElectronやReact、TypeScriptを採用しました。 アプリは内部でサブプロセスとして声変換エンジンを動かしており、サブプロセスとの通信はキューで制御されています。 Electronのメインプロセスでキューを非同期で扱えるようにしており、開発のしやすさや、UXの向上に繋げています。
チーム開発を行うのは初めての経験でした。スクラム形式でタスク管理を行い、使用するライブラリの選定から取り組みました。
開発を進める中で社内の開発リポジトリが全て閲覧可能だったことはとても役に立ちました。 DMVが開発しているSeirenVoiceを参考に、プロのエンジニアがどのようにライブラリを管理し、コードを書いているのかを学びました。
今回のアプリでは、エンジンとの通信にキューを使っていますが、このキューは自分なりに試行錯誤して自作しています。 開発中にいくつかバグが見つかり、バグ修正の方向性に悩んでいたところ、SeirenVoice の開発に関わる戀塚さんとペアプロさせていただく機会を得ました。 ペアプロの中で具体的にアドバイスを得てバグを修正することができ、アルゴリズムの組み方や、組む際の注意点などの実践的な知識を学ぶことができました。
さらに、BLAS などの関連技術に触れられました。 そういった技術に触れる際、困ったことがあれば身近に頼れる方もいて、エンジニアが数多く在籍する企業の強みを実感しました。
アプリ開発が一息ついたところで、現状の声変換エンジンに課題があるという話を伺いました。
それは音声変換による品質と速度、制御性のトレードオフの問題です。
その問題の解決に取り組んでいる、個人的にも気になっている論文があると紹介したところ、信号処理を導入したニューラルボコーダーの実装と品質の評価を任されました。
実装したコードはGitHubでOSSとして公開しています。
https://github.com/DwangoMediaVillage/mlsa_neural_vocoder/
信号処理とニューラルネットを組み合わせてEnd-to-endで音声合成する機械学習手法が2023年に提案されました [1]。 この論文では、ドメイン外データに弱く、制御性が損なわれるというニューラルボコーダの課題に対して、Mel-Log Spectrum Approximation(MLSA)フィルタという信号処理フィルタを微分可能にしてモデルに埋め込むことで品質向上を図っています。 MLSAフィルタは入力された対数振幅スペクトルに近似するように音声を合成・変換するフィルタです。 このような信号処理を組み合わせることで、品質と速度のトレードオフを減らせたり、信号処理的な操作によって新しい話者を作ることができたりします。 論文の成果は声変換やTTSなどにも応用可能であると考えられたので、実装し性能を評価しました。

論文ではテキスト処理や音響特徴量予測のためのモジュールを含めたアーキテクチャが提案されていますが、今回は音響特徴量 (基本周波数: f0、メルケプストラム、非周期性指標: Aperiodicity) から音声を合成する「ボコーダー」の部分に着目しました。 この変更にあたり、音響特徴量から Latent variables を計算するための全結合層(Linear)を追加しています。 このモデルではf0からパルス波を生成し、パルス波に対して非周期性指標を用いて周期性信号を作ります。 周期性信号をニューラルネットであるPrenetに通し、周期性信号を改善します。 同様のことをパルス波と同じ長さのノイズに対して行い、非周期性信号を作ります。 周期性信号と非周期性信号を合成して作成した励起信号と、メルケプストラムをメルケプストラム合成フィルタに通すことで、最終的な音声が生成されます。 Prenet のネットワーク構造や損失関数については論文の提案と同じものにしました。 また、学習率スケジューラーとして WarmupCosineAnnealing を、Optimizer として AdamW を用いました。
モデルの構築にあたっては、論文とともに公開されたライブラリである「diffsptk」を活用しました。 MLSA フィルタは論文で利用されているテイラー展開ではなく、diffsptkに実装されているSTFTを用いる手法を利用しました。 こちらのほうが高速で精度も差がなかったためです。
データセットはJVS100 [2] を用い、サンプリングレートは24kHzのまま使用しました。
前処理として、各データから音声分析合成器の WORLD を用いてスペクトル包絡、非周期性指標、f0を抽出し、信号処理ツールキットの SPTK を用いてスペクトル包絡はメルケプストラムに、非周期性指標はメル尺度に変換しました。
これらの前処理で得た特徴量から音声を合成するように学習しました。
オリジナル音声(GT)と作成したモデルの音声(MLSA w/ Prenet)を比較しました。GTと比べると、全体的に不自然さがあり、何らかのノイズが付加されてしまっていることがわかりました。
| Name | GT | MLSA w/ Prenet |
|---|---|---|
| jvs006 | ||
| jvs007 |
実験1で示したように、今回の実験条件だと、単にMLSAニューラルボコーダーを組み込むだけでは、ノイズが出ることがわかりました。

各フィルタやニューラルネットの出力を分析・調査したところ、非周期性信号のPrenetでパルスのようなノイズが付加されてしまっていることが問題でした。 Fig4はFig3の音声と同じ範囲の非周期性信号のPrenetの出力を図にしたものです。一見ホワイトノイズのように見えますが、Fig3のパルス状のノイズと同じタイミングでノイズが現れていることがわかります。
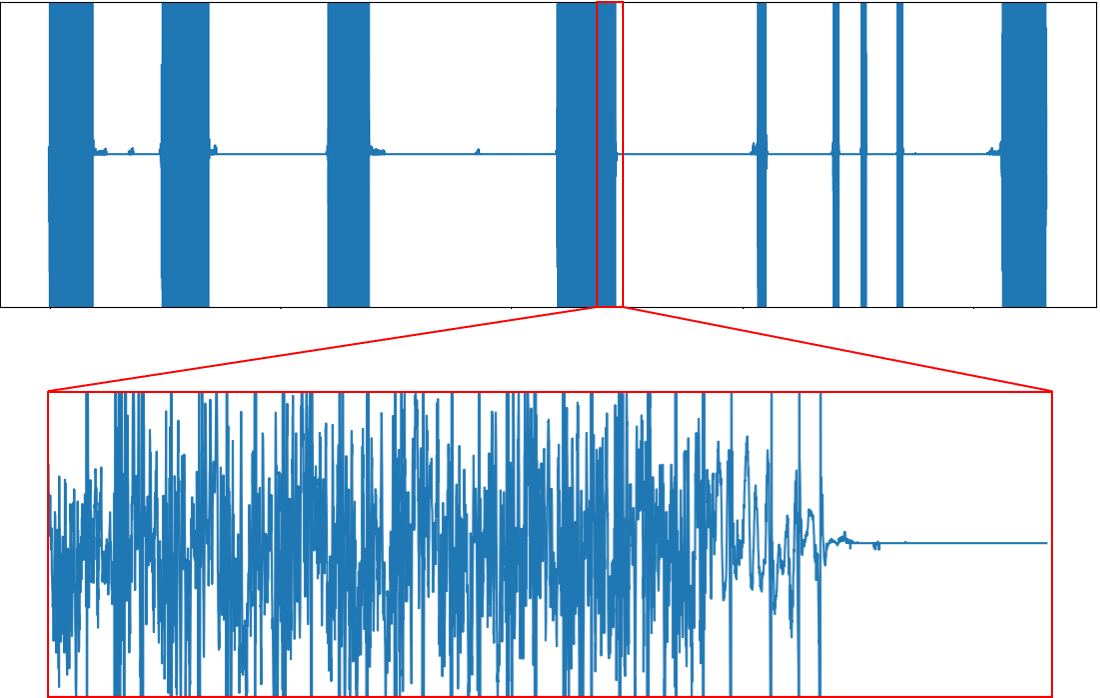
これらのパルス状のノイズは、スペクトログラム領域での損失最小化だけでは抑制するのが難しいと考えました。
このようなアーティファクトに対応する手法としてよく GAN (Generative Adversarial Networks) が用いられます。
その前例に倣い、GANを導入しました。
いくつかの構成を試し、UnivNet [3]と同一の構成を採用しました。GANの導入により、Prenetの周期的ノイズは解消しました。
また、GTにかなり近づいており、ほとんど差がないレベルの品質になりました。
GANによってPrenetの性能をさらに引き出せていると考えられます。

ここからは、作成したモデルと信号処理的な操作を組み合わせ、結果を聴き比べていきます。 まずは、信号処理的な操作を行わないベース音声について、以下の5条件を聴き比べます。 また、CPU上での平均RTF(Real Time Factor)についても計測・比較します。
| Name | GT | WORLD | MLSA | MLSA w/ Prenet | MLSA GAN |
|---|---|---|---|---|---|
| jvs006 | |||||
| jvs007 | |||||
| RTF | - | 0.100 | 0.008 | 1.097 | 1.093 |
MLSAは少し籠った感じの音声になり、WORLDでは少し機械音声感がありますが、MLSA GANはそれらの問題がほとんどなく、自然性がかなり高く感じられます。
次に、信号処理的な操作について検証します。今回は、f0の変更、フォルマントシフトやスペクトル傾斜の変更、非周期性指標のスケールを試します。 今回は、以下の4条件について比較します。
ここでは、大きく差が出た非周期性指標のスケールについてのみ取り上げます。 全ての音声はAppendixにまとめてありますので、気になった方はご覧ください。
| Name | WORLD | MLSA | MLSA w/ Prenet | MLSA GAN |
|---|---|---|---|---|
| jvs006 ×0.5 | ||||
| jvs006 ×1.5 | ||||
| jvs006 ×2.0 | ||||
| jvs007 ×0.5 | ||||
| jvs007 ×1.5 | ||||
| jvs007 ×2.0 |
全体として、MLSA GANやMLSA w/ Prenetで合成された音声は、既存手法のWORLDやMLSAで得られる結果とほぼ同じ結果が得られており、Prenetの導入によって信号処理的な操作に影響が出ることはあまりないということがわかります。 また、これらの操作をしてもなおMLSA GANは既存手法のWORLDよりも高い品質がでていると感じられます。 非周期性指標をスケールした場合に関して、MLSA w/ Prenetではかなり不自然になりますが、MLSA GANではかなり改善されています。 この点から、音声品質の向上に非周期性信号の改善が寄与していると思います。
研究に取り組む前は信号処理に基づく音声分析合成について、漠然とした理解にとどまっている部分がありました。 取り組み始めた時点では、モデルを実装するための知識が足りておらず、一人で実装しきることは難しい状況でした。 しかし、上長やメンターの方を頼りに勉強し、実装に落とし込むことができました。
実験結果の分析についても、メンターの方に教えていただく機会がありました。 実際にメンターの方が分析した手法や、実験結果を見せていただくことで、今後研究に取り組む上で非常に役立つ実践的なスキルを学ぶことができました。
インターン全体を通して、研究と開発両方に触れることができました。 研究か開発か、どちらかを選ぶのが難しい私にとって、どちらもできるという環境はDMVという部署の魅力であると感じました。 ほぼフルリモートながら、中身が濃い体験をさせていただけたと思います。 メンターの方を中心に、様々な方と関わりを持ち、頼ったりお話したりと、とても楽しいインターン期間でした。
最後になりますが、メンターの方を始め、DMVの皆さん、関わっていただいたすべての方々に感謝し、本稿の締めとさせていただきます。 ありがとうございました。
[1] Takenori Yoshimura, Shinji Takaki, Kazuhiro Nakamura, Keiichiro Oura, Yukiya Hono, Kei Hashimoto, Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis System, ICASSP 2023 https://ieeexplore.ieee.org/document/10094872
[2] Shinnosuke Takamichi, Kentaro Mitsui, Yuki Saito, Tomoki Koriyama, Naoko Tanji, and Hiroshi Saruwatari, JVS corpus: free Japanese multi-speaker voice corpus https://arxiv.org/abs/1908.06248
[3] Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, Juntae Kim, UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation, Interspeech 2021 https://www.isca-archive.org/interspeech_2021/jang21_interspeech.html
信号処理的な操作をした音声を掲載します。
| Name | WORLD | MLSA | MLSA w/ Prenet | MLSA GAN |
|---|---|---|---|---|
| jvs006 ×0.5 | ||||
| jvs006 ×0.75 | ||||
| jvs006 ×1.25 | ||||
| jvs006 ×1.5 | ||||
| jvs007 ×0.5 | ||||
| jvs007 ×0.75 | ||||
| jvs007 ×1.25 | ||||
| jvs007 ×1.5 |
| Name | WORLD | MLSA | MLSA w/ Prenet | MLSA GAN |
|---|---|---|---|---|
| jvs006 -3.0dB | ||||
| jvs006 -6.0dB | ||||
| jvs006 +3.0dB | ||||
| jvs006 +6.0dB | ||||
| jvs007 -3.0dB | ||||
| jvs007 -6.0dB | ||||
| jvs007 +3.0dB | ||||
| jvs007 +6.0dB |
| Name | WORLD | MLSA | MLSA w/ Prenet | MLSA GAN |
|---|---|---|---|---|
| jvs006 ×0.50 | ||||
| jvs006 ×0.70 | ||||
| jvs006 ×1.41 | ||||
| jvs006 ×2.00 | ||||
| jvs007 ×0.50 | ||||
| jvs007 ×0.70 | ||||
| jvs007 ×1.41 | ||||
| jvs007 ×2.00 |

Yuto Ashida