| 入力音声 | 目標音声 | 既存手法による変換 | 提案手法による変換 |
|---|---|---|---|
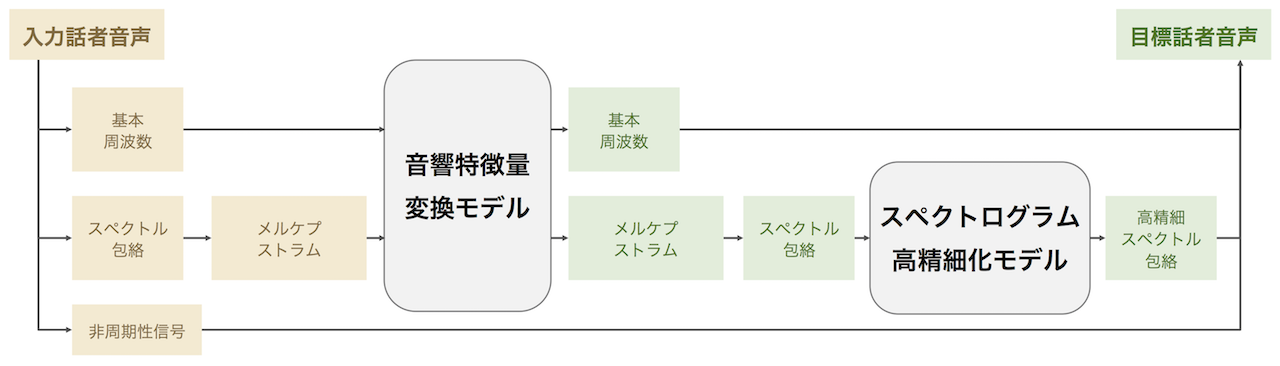
本研究では,少数のパラレルデータで学習可能な声質変換モデルと,多数のノンパラレルデータで学習可能な高品質化モデルに分けることで,必要なパラレルデータ数を抑えつつ高品質な声質変換を行う手法を提案する。1段目のモデルでは,時間方向に1次元畳み込み層を持つ畳込みニューラルネットワーク (CNN) を用いて,時間的な依存関係を考慮しつつ,入力話者の基本周波数と低次のメルケプストラム系列を目標話者のものに変換する.2段目のモデルでは,GANを用いて,過剰に平滑化された変換時の音響特徴を高精細化する.実験結果から,従来手法と比べ,提案手法は同程度の自然性と高い個人性を持つ声質変換が可能であることを示した.
主観評価実験により,変換音声の自然性と個人性をそれぞれ比較した.自然性は音声が自然に聞こえるか,個人性は音声が目標話者らしく聞こえるかを表した指標である.変換音声の自然性をABテストにより評価した.従来手法および提案手法で変換された音声をランダムな順序で再生し,高い自然性を持つ変換音声を被験者に選択させた.また,変換音声の個人性をXABテストにより評価した.目標の音声を再生した後に,従来手法と提案手法により変換された音声をランダムな順序で再生し,目標音声と似ている変換音声を被験者に選択させた.被験者9名は15対の音声に対してそれぞれ評価を行った.従来手法には,GMMを用いた差分スペクトル手法 sprocket [2] を用いた.従来手法のモデルの学習には50文のパラレルデータを用いた.提案手法には,高精細化モデルの学習データ数を変えて,2種類のモデルを用いた.
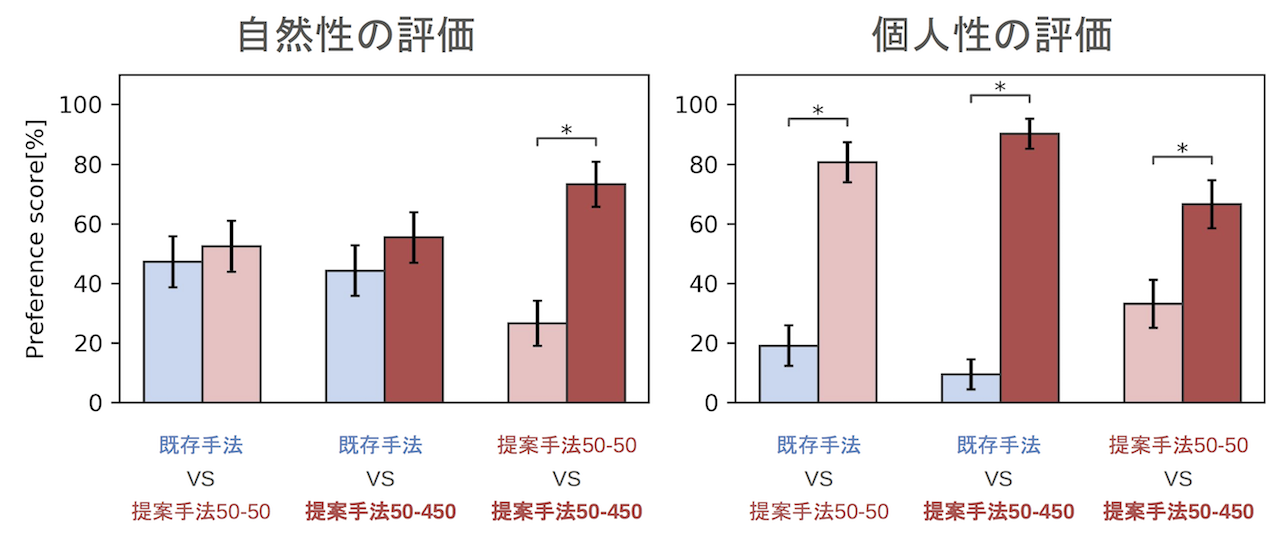

提案手法の変換音声は,従来手法の変換結果に比べて,同程度の自然性と,高い個人性を持つことがわかった.学習に用いる目標話者の音声データ数を増やすことで,より自然性・個人性の高い変換音声が得られた.
公開許諾をいただけたので,あらたに 声優統計コーパス [3] で学習したサンプル音声も載せる.入力音声は著者(20代男性)の音声を用いた.提案手法を使って,私の声の録音データと声優統計コーパスを学習データとし,私の声をプロの女性声優の声に変換した.比較用に,sprocketを用いて変換した結果も紹介する.声優統計コーパス100文のうち,95文のパラレルデータを用いて学習し,残り5文をテストデータとした.目標音声は,声優統計コーパスのtsuchiya_normal_001.wav〜tsuchiya_normal_005.wavを,16000Hzにリサンプリングした音声データである.論文中での450文の実験と異なり声優統計コーパスが100文だったため,既存手法と明確な差は出ていないかもしれない.
提案手法の場合は,目標話者のノンパラレルデータを増やせば,変換結果の質を上げることも可能だろう.
| 入力音声 | 目標音声 | 既存手法による変換 | 提案手法による変換 |
|---|---|---|---|
[*] 論文の著作権は情報処理学会に帰属します
[1] Morise, M., Yokomori, F. and Ozawa, K., WORLD: a vocoder-based high-quality speech synthesis system for real-time applications, IEICE T INF, 2016. https://github.com/mmorise/World
[2] K. Kobayashi, T. Toda, sprocket: Open-Source Voice Conversion Software, Proc. Odyssey, 2018. https://github.com/k2kobayashi/sprocket
[3] y_benjo and MagnesiumRibbon, 声優統計コーパス, 2017. https://voice-statistics.github.io/