この研究では,写真を入力として,3Dのポーズを推定する手法を提案します.中でも,2Dのポーズの推定は近年盛んに行われているので [Cao2017],推定された2Dポーズを3DにLiftする手法を提案しました.このような手法は従来から提案されていたのですが [Martinez2017],それらは必ず学習時に3次元データセットを用いていました.我々は,学習時にも推定時にも3Dのデータが全くいらない3Dポーズ推定の手法を初めて提案します.
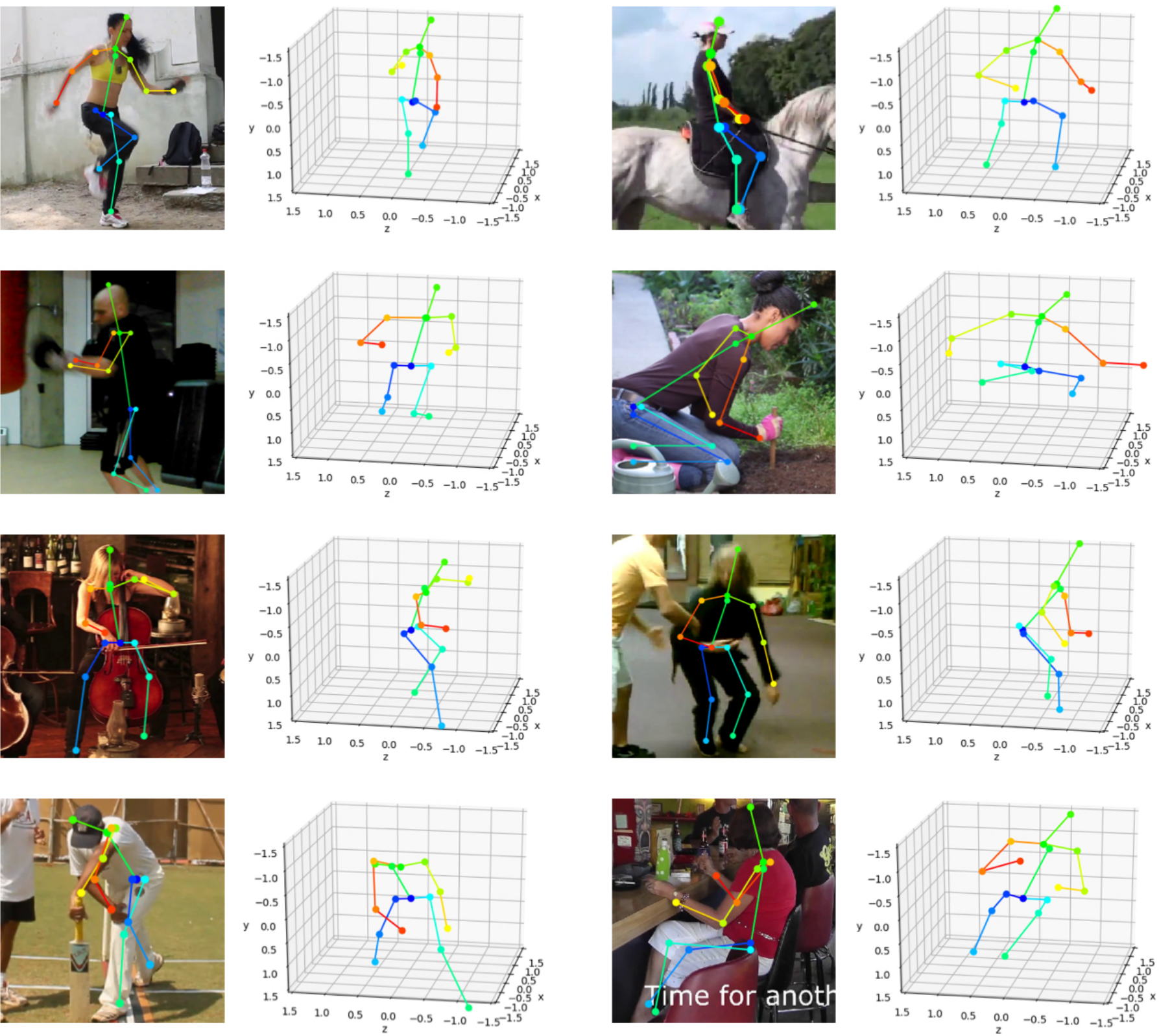
2Dポーズのデータセットで学習し、3Dポーズを推定したもの。入力(画像中に表示されている)の2Dポーズは推定したものではなく、データセットで与えられている。
この画像は,2Dポーズのデータセット MPII Human Pose Dataset のデータを我々の手法で3D化したものです.学習時にもこの2Dのデータしか用いてないにも関わらず,複雑なポーズでも破綻なく3D化されていることがわかるかと思います.
この動画中では,撮影された画像に対して,openpose [Cao2017] を用いて推定された2Dのポーズ(左下)に加えて,そこから3Dポーズを推定して得られた,新たな三方向からのポーズを図示しています(左上).openposeによる2Dのポーズ推定が成功している部分については,他の方向から見ても破綻のない3Dポーズになっています.

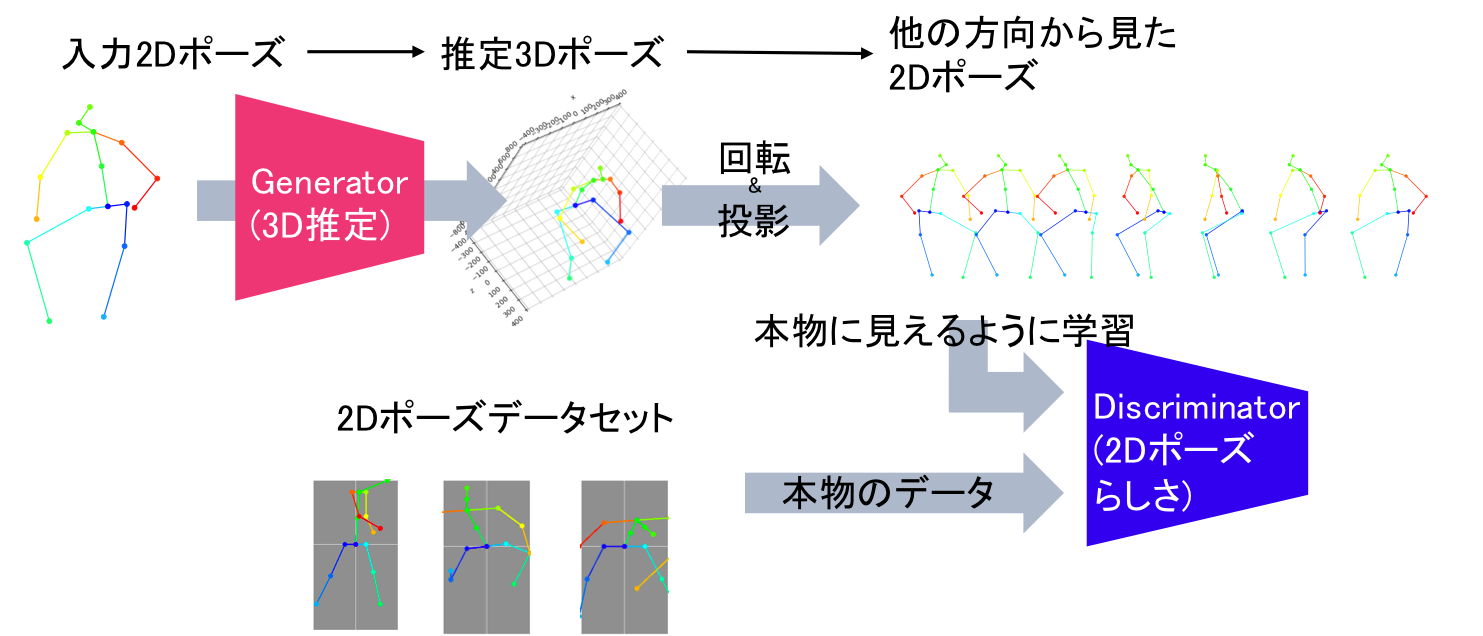
ここからは,3Dデータセットを利用せずに3Dを学習する方法について説明します.基本的なアイディアは正しい3Dポーズは,どの方向からみても正しい2Dポーズになっているというもので,正しい2Dポーズの範囲を2Dデータセットから学習すれば,3Dポーズの推定は,その制約に沿うように推定すればいいということです.正しい2Dポーズの範囲の学習には,Generative Adversarial Network(GAN) [Goodfellow2014] の仕組みを用います.この仕組みでは,Generatorによって推定された2Dポーズであるか,それとも2Dデータセットにもとも存在するポーズであるかを識別するDiscriminatorを用い,そのDiscriminatorを騙すようにGeneratorを学習することで,Generatorが生成する2Dポーズが,破綻のないものになります.
ただし,3Dポーズの推定も直接ニューラルネットワークで行います.つまり,Discriminatorは2Dポーズの識別なのですが,それを騙すように3DポーズをGeneratorが生成します.この間のギャップを埋めるのが,微分可能なProjectionです.幸い,3Dポーズは各関節の3次元座標なので,これを微分可能な形でいろいろな方向に射影することは難しくありません.よい3Dポーズはあらゆる方向にProjectionしても破綻のない2Dポーズになるはずですが,今回は,人間のポーズを求めているため,頭は上を向いていることが多いだろうと判断し,胴体周りでランダムに回転させたときのProjection結果がDiscriminatorを騙せるようにGeneratorをトレーニングしました.
@misc{kudo2018,
Author = {Yasunori Kudo and Keisuke Ogaki and Yusuke Matsui and Yuri Odagiri},
Title = {Unsupervised Adversarial Learning of 3D Human Pose from 2D Joint Locations},
Year = {2018},
Eprint = {arXiv:1803.08244},
}
[Cao2017] Cao, Z., Simon, T., Wei, S.E., Sheikh, Y.: Realtime multi-person 2d pose estimation using part affinity fields. In: CVPR. (2017) https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation
[Goodfellow2014] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative Adversarial Nets. In: NIPS. (2014) https://papers.nips.cc/paper/5423-generative-adversarial-nets
[Martinez2017] Martinez, J., Hossain, R., Romero, J., Little, J.J.: A simple yet effective baseline for 3d human pose estimation. In: ICCV. (2017) https://arxiv.org/abs/1705.03098