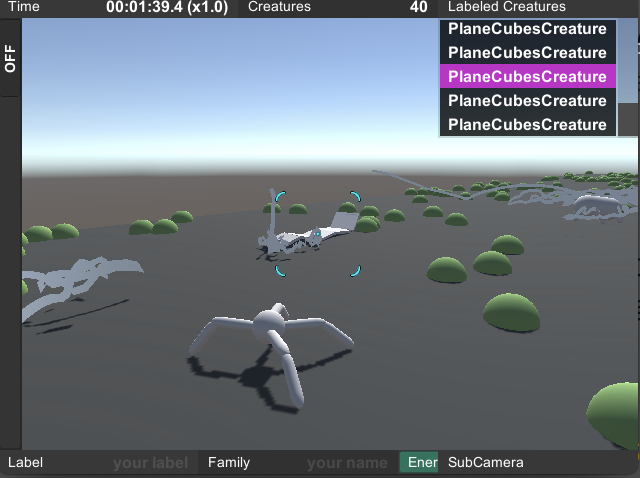
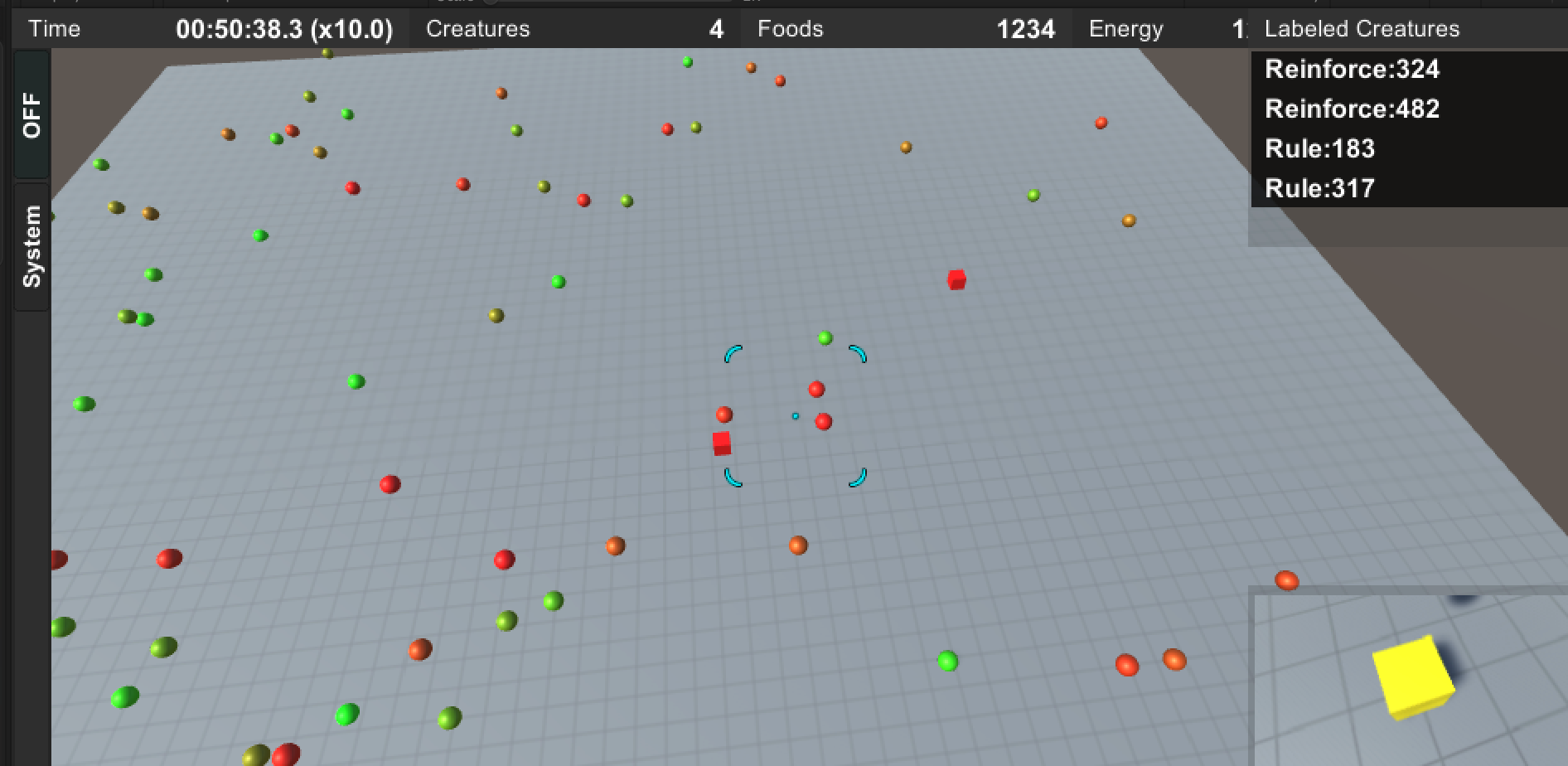
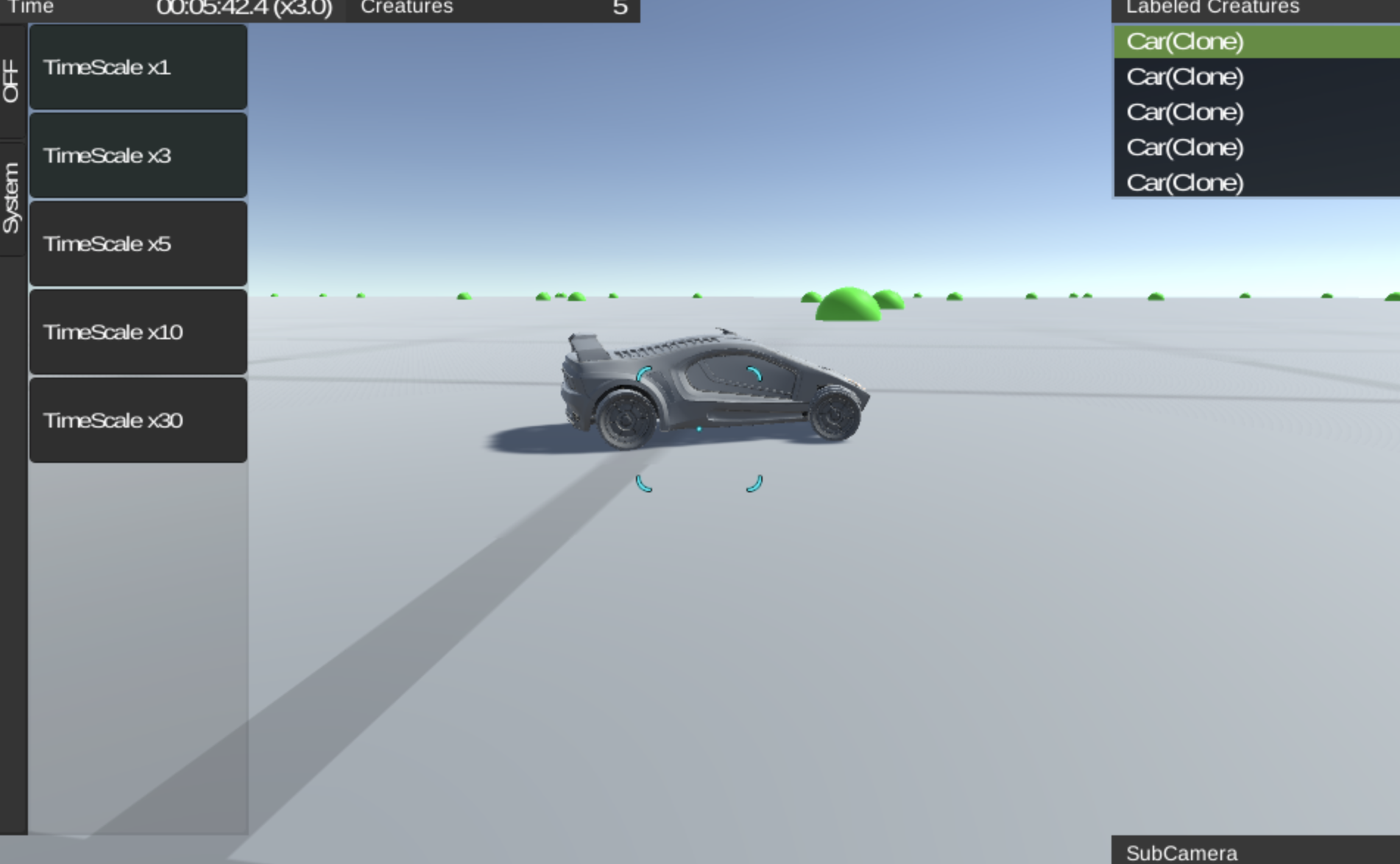
仮想の未知の生物でも,我々はその形状から自然な動きを想像することができる.この研究では,そのような,未知の形状の生物に対して自然な動きを与える手法を提案します.自然な動きを,効率の良い動きと考え,なるべく短時間で目的(報酬)を最大化する動きを深層強化学習で得ます.
近年このような深層強化学習による運動生成はいくつか研究が行われています.本研究では特に,スマートフォンなどのモバイル環境で実行可能な,運動生成のための深層強化学習手法を提案します.
ここで報酬とは,たとえば未来に渡っての餌の獲得量など.その報酬を最大化するための出力は,それぞれの生命のすべての関節の,毎フレームでの角度となります.しかし,未来に渡っての報酬を予測して最大化すること,すべての関節をすべてのフレームについて決めること,は非常に難しい問題であるため,限られた計算資源でこの問題を解くために我々は問題を2つに分割したシステムを提案します.
報酬を最大化するために,“前進”・“ジャンプ"など離散化された行動指示を数十フレームごとに決定する強化学習部分(Decision-Maker).それより細かい数フレームごとに,その数フレーム内だけで行動指示内容をなるべく達成するための探索(バンディットアルゴリズムを用いる)部分(Sequence-Maker).2つの複雑さをこの2つの学習アルゴリズムがそれぞれ分担して解くことによって,モバイル環境で数十体の人工生命がリアルタイムに学習することを達成しました.
8/12日から開催された[SIGGRAPH 2018のStudio]にて,ドワンゴではこの研究の展示と発表を行いました.
https://github.com/dwango/RLCreature
Unityのコードとして人工生命のデモと、その中で用いられている要素技術である2つのライブラリをオープンソースとして公開します。
https://github.com/dwango/MotionGenerator
学習部分のエンジンで,本研究の中心であるDecision-Maker, Sequence-Makerがそれぞれ実装されています.本研究のようにSequence-MakerとDecision-Makerを協調して動かすことも,Sequence-Makerだけで単純な問題を解くことも,Decision-Makerの行動計画機能だけを利用することもできます.
https://github.com/dwango/TinyChainerSharp
“スマートフォンで学習可能な人工生命"という目標を達成するために,我々はスマートフォン上で"学習"可能なライブラリを探す必要がありました.現在スマートフォンで利用可能な深層学習ライブラリとしてはTensorFlowLite, iOS CoreML, Unity ml-agentなどが挙げられると思いますが,そのどれもが推論機能のみのサポートで,学習機能はスマートフォンでは利用できませんでした.そこで,様々な深層学習ライブラリの内,ソースコードが読みやすく,理解しやすいChainerを参考として,必要最低限の機能をUnity(C#)に移植することにしました.完成したのがTinyChainerSharpです.このライブラリは本当に必要最低限の機能で,たとえば画像認識などで最もよく利用される,畳み込みニューラルネットワークもまだ実装されていませんが,非常にコンパクトでクロスプラットフォームでコンパイルすることができます.
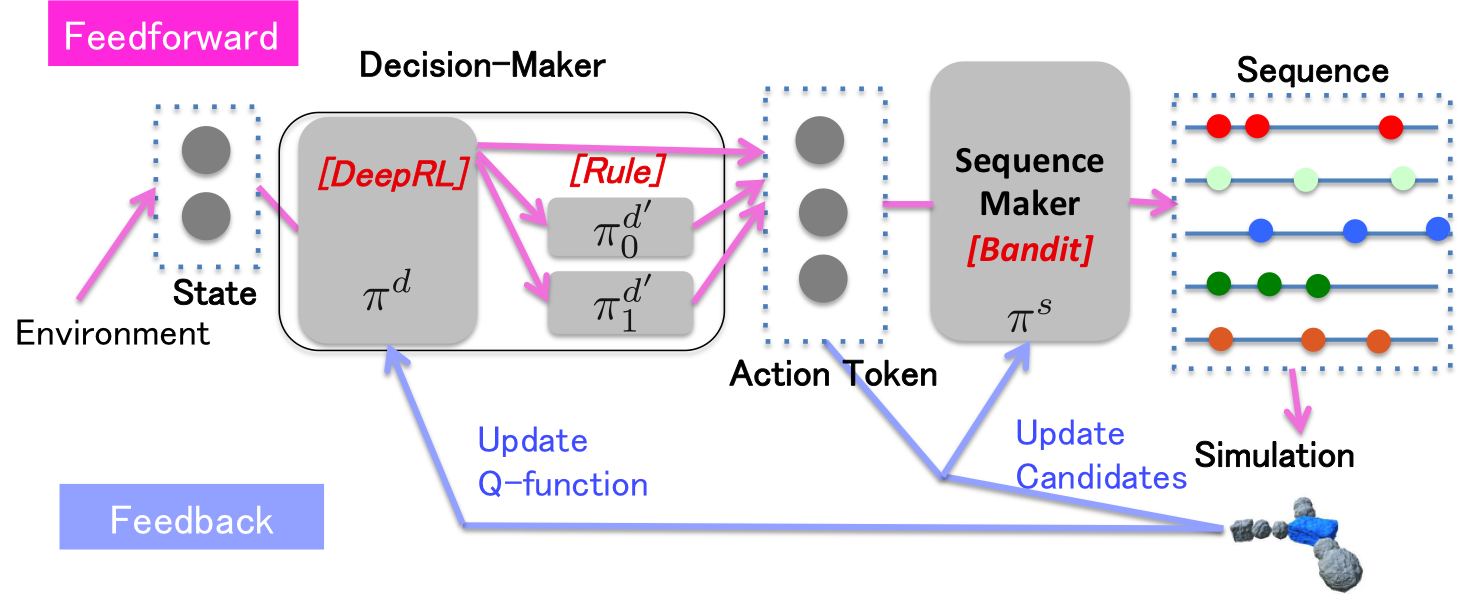
ここでは,概要で説明した技術についてもう少し詳細な説明を加えます.図のように,環境からStateを受け取って,前進などのAction-Token単位の指示に分解するDecision-Makerと,Action-Tokenを具体的な関節角度へと翻訳するSequence-Makerの2つの問題があります.
Sequence-Makerは,Decision-Makerが数十フレームに一度出してくる,大雑把なAction-Tokenを,数フレームごとの関節の目標角度という具体的な指示に落とし込むものです.ここで,Action-Tokenは,たとえば前進であれば,その生命にとっての正面方向への移動量,のような1次元の即時評価可能な評価値とセットになっています.それにより,Sequence-Makerは1回のAction-Token指示をこなすごとに,即,評価を得られ,それによりモデルを更新することが可能です.(数十フレームの関節位置, 評価値)という無限の組み合わせの中から,最も期待評価値の高いものを選び出す,という風に考え,学習アルゴリズムは無限腕バンディットアルゴリズムを利用します.
Decision-Makerは,映像のように,より長期間の高次な報酬,たとえば"30秒後に餌を獲得できた”,などを満たすための仕組みです.Decision-Makerの出力は,有限のAction-Tokenから1つを選ぶというものであり,このような,頻度が稀に与えられる報酬について,有限の選択肢から最適なものを選び続ける問題は典型的な強化学習の問題と言えます(たとえば迷路を想像して下さい).ここでは,ビデオゲームの操作で大きな成功をした[DQN]を利用します.
@inproceedings{ogaki2018,
author = {Keisuke Ogaki and Masayoshi Nakamura},
title = {Real-Time Motion Generation for Imaginary Creatures Using Hierarchical Reinforcement Learning},
booktitle = {ACM SIGGRAPH 2018 Studio},
year = {2018},
publisher = {ACM}
}
[1] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles BeaÂŁie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. Human-level control through deep reinforcement learning. Nature 518 (2015),
[2] Tokui, S., Oono, K., Hido, S. and Clayton, J., Chainer: a Next-Generation Open Source Framework for Deep Learning, Proceedings of Workshop on Machine Learning Systems(LearningSys) in The Twenty-ninth Annual Conference on Neural Information Processing Systems (NIPS), (2015)