
Dwango Media Villageでは,任天堂様から発売されているゲーム「スプラトゥーン2」に関する研究を行っており,その成果として,昨年行われた公式大会「第4回スプラトゥーン甲子園」にて「AIによる各地区代表チームの戦略分析」を公開した.
本研究において,チームの戦略を分析するために,まず試合中の優勢劣勢状況を定量的に評価する必要があった.スプラトゥーンはわかりやすいながらも奥が深いゲーム性を持っており,単純な塗り面積の差などでは優勢劣勢状況を判断できず,定量的に評価することは難しい.そこでスプラトゥーン甲子園の配信映像を学習データとして,ゲームの各時点のフレーム画像から勝敗を予測するモデルを作成し,チームの戦略分析に活用する手法を提案した.その結果,学習した勝敗予測モデルは3分間の試合全体を通じて7割程度の精度で勝敗の予測が可能であり,チームの戦略分析に応用することができた.
この記事では,まず作成した勝敗予測モデルについて説明し,次に勝敗予測モデルを元にしてどのようにチームの戦略分析を行ったのかを説明する.
勝敗予測モデルを作成することで,今回のチームの戦略分析のような応用や,試合の解説者が参考に用いるためのデータとして用いるなどの活用が考えられる.
「スプラトゥーン」は4対4で分かれてインクを塗り合うアクションシューティングゲームである.スプラトゥーンの公式大会である「スプラトゥーン甲子園」では,3分間の試合の後,床をより多くのインクで塗っていたチームが勝ちとなる「ナワバリバトル」ルールが採用されている.
ナワバリバトルは非常に明快なルールだが,上級者によるレベルの高い戦いにおいては,スプラトゥーンをよく知るプレイヤーでもどちらのチームが有利なのかを判断するのが難しい場合がある.具体的には,ある時点の床の塗り面積だけではなく,ステージによって異なる有利なポジションを確保しているかどうか,チームの人数差による戦力差,戦況を大きく左右する「スペシャルウェポン」を発動できるかどうかなど,多くの情報から総合的に判断する必要がある.
この「シンプルかつ奥が深い」のがナワバリバトルの非常に面白いところではあるが,勝敗予測モデルを作成することで,よりこのゲームを楽しみやすくなると考えた.

勝敗予測モデル,つまりゲームの局面からその局面の良し悪しを計算する評価関数を作成する手法について,他のゲームの例を挙げる.コンピュータ将棋では,Bonanza [Hoki2006] が局面の特徴から局面の良し悪しを計算する評価関数を,プロ棋士の棋譜を用いて学習する「教師あり学習」のアプローチによって成功を収めた.コンピュータ囲碁では,AlphaGo Zero [Silver2017†] の前身となる AlphaGo [Silver2016] では人間のプロの棋譜から評価関数を学習した.
本研究では,これらの例のように,既に存在する試合のデータを使って評価関数を学習する「教師あり学習」のアプローチを選択した.
教師データとして,プレイヤーの皆さんが配信しているスプラトゥーンの試合動画とその勝敗を用いることが考えられるが,プレイヤー視点の動画を用いることには問題がある.それは,プレイヤー視点の動画だけでは局面の状態が完全には含まれていないという点である.
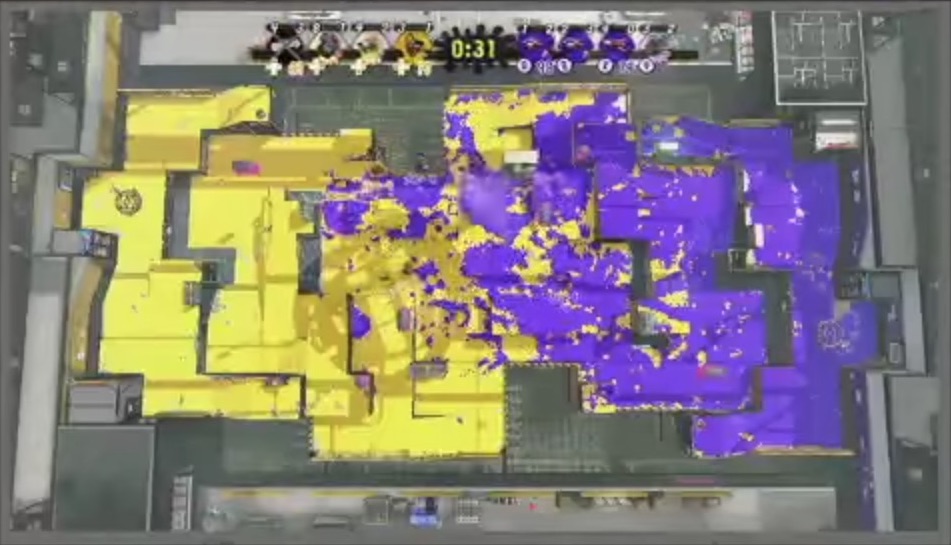
そこで,ステージの「俯瞰マップ」映像を得ることができる,スプラトゥーン甲子園の配信映像を教師データとして用いた.俯瞰マップには,残り時間・ステージ全体の塗り状況・プレイヤー8人の位置・生存状況・スペシャルウェポンの保持状況などの局面の情報をほぼ全て含んでおり,局面の特徴として用いることができると考えられるためである.
スプラトゥーン甲子園の配信映像からトリミングした俯瞰マップの画像を入力として,入力された画像の試合でどちらのチームが勝利するかを予測するモデルを学習した.例えば将棋の評価関数では,「王とそれ以外の2駒の位置関係」などを特徴量としてゲーム状態を離散化したりする例があるが,スプラトゥーンにおいては自明な離散化の方法がないため,連続値の画像をそのまま入力とし,畳込みニューラルネットワークで扱った.

学習は,VGG16 [4] のモデルを用いた転移学習で行った.モデルの入力には,3分間の試合の映像を1フレームずつ切り出した画像を用いた.つまり,俯瞰マップの画像1フレームに対して「その試合はどちらのチームが勝ったか」を教師ラベルにして学習する.学習データの画像の枚数は,評価用の試合や,後述する戦略分析のために地区大会代表チームの準決勝・決勝の試合を除外した約390試合から得た約199万枚である。
学習の結果,学習に用いていない評価用の試合での正答率が約73%となった.この正答率は,ほとんど有用な情報がない試合開始直後から試合終了の3分間を均等に評価しての数値であり,かなり予測を的中させられているものと考えられる.
作成したモデルは,俯瞰マップの画像を1枚入力すると局面の優勢劣勢を示す評価値を1つ出力し,この値が0.5より大きければ黄色チームが有利,0.5より小さければ青色チームが有利であることを示す.このモデルに,試合が開始してから終わるまでの俯瞰マップの画像を入力していき,出力した評価値をプロットすると,次のようなグラフを描くことができる.

描かれたグラフを見ることで,例えば「試合開始約X秒後に青色チームが打開を決めたが,すぐに黄色チームは立て直した」や「残り30秒まで黄色チームは劣勢状況が続いていたが,残り30秒から一気に打開して勝利した」などの1試合ごとの分析が可能である.
勝敗予測モデルによって,1試合ごとの局面分析が可能になったが,チームの戦略分析においては,そのチームが戦った複数試合に共通するような特徴を抽出して可視化する必要がある.スプラトゥーン甲子園のような大会でのナワバリバトルでは,序盤から敵チームを制圧して抑え続けるチームや,何度もチームワークで打開を試みるチーム,序盤に制圧されてもスペシャルウェポンなどを蓄えてラスト30秒に全てをかけて打開するチームなど,チームごとに様々な戦い方が行われており,これらをうまく特徴づけられるように指標を作る必要があった.
そこで今回の研究では,地区大会の代表チームの準決勝・決勝の試合について上の図のような評価値の推移を計算し,チームの戦略を表現する5つの指標を計算した.

ここで算出した戦略分析の結果は,実際にスプラトゥーン甲子園の優勝チーム予想企画の参考データとして公開された.

生放送の様子はこちら.各地区大会の代表チーム全16チームに対して,チームの戦略を表現する5つの指標を計算し,レーダーチャートで可視化した.
スプラトゥーンを題材にしたゲームの勝敗予測モデルを作成し,これを利用してチームの戦略分析を公開した.
今回はスプラトゥーンを対象にしていたが,他のビデオゲームタイトルにも同様の手法を活用できる可能性はある.近年,対戦ゲームタイトルのe-Sports化が盛んに行われており,非常にレベルの戦い試合がたくさん行われている.これらの試合を客観的な視点で可視化することで,観戦しているプレイヤーが上級者のプレイをより楽しめるようになることが期待される.
また,今回作成したモデルだけでは,どちらかのチームが優勢であることは出力できるが,その理由は人間の解説者が解釈する必要がある.これはGrad-CAM [Selvaraju2017] のようなCNNの判断根拠を可視化する手法を適用することで,「ここのポジションを確保しているおかげで,黄色チームが優勢と評価されている」などのような解説を簡単に行うことができるようになることが期待できる.
この研究は Dwango Media Village でインターンをしておりました藤村が行いました.半年間,DMVの方々に協力していただき,研究を進めることができました.ありがとうございました.
スプラトゥーンは,私がシリーズを通して4000時間ほどプレイしている大好きなゲームで,公式大会の企画に微力ながら協力させていただけることになり,とても嬉しかったです.最後になりますが,この場を借りて関係者の皆様にお礼申し上げます.本当にありがとうございました.
[Hoki2006] 保木邦仁:局面評価の学習を目指した探索結果の最適制御,第 11 回ゲームプログラミングワークショップ 2006, pp. 78–83 (2006). https://ipsj.ixsq.nii.ac.jp/ej/index.php?active_action=repository_view_main_item_detail&page_id=13&block_id=8&item_id=97627&item_no=1
[Silver2017] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L., van den Driessche, G., Graepel, T. and Hassabis, D.: Mastering the game of Go without human knowledge, Nature, Vol. 550 (online) (2017). http://dx.doi.org/10.1038/nature24270
[Silver2016] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T. and Hassabis, D.: Mastering the game of Go with deep neural networks and tree search, Nature, Vol. 529 (online) (2016). http://dx.doi.org/10.1038/nature16961
[Karen2014] Karen Simonyan, Andrew Zisserman: Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR abs/1409.1556 (2014). https://arxiv.org/abs/1409.1556
[Selvaraju2017] Selvaraju, Ramprasaath R., et al. "Grad-CAM: Visual explanations from deep networks via gradient-based localization." 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017. https://ieeexplore.ieee.org/document/8237336
† AlphaGo Zero は人間の棋譜を全く使わずに,自己対戦による強化学習で評価関数を学習した.
Yutaro Fujimura