強化学習は適切な方策を学習するまでに膨大な試行回数が必要だが,模倣学習を組み合わせることで探索コストを削減できることが知られている.しかし模倣学習を行うには,ラベル付きデータセットが必要でありデータの収集コストが高い.NeurIPS 2022 で発表された Video Pre Training (VPT) [1] は,比較的収集コストの低いラベルなし動画から半教師あり模倣学習を行うことで,データの収集コストを抑えている.今回は強化学習の代表的なベンチマークである Atari 2600 のゲームに対して実験を行い,VPT の有効性を確認した.
VPT はデータ収集コストの低い,行動ラベルがついていない人間のゲームプレイ動画から模倣学習することを提案している.状態から行動を予測する Inverse Dynamics Model (IDM) を用いてラベルなし動画に擬似的な行動ラベルを付与して模倣学習する.これにより,従来の強化学習や模倣学習では攻略できなかった Minecraft におけるダイヤモンドピッケル収集タスクを初めて達成し話題となった.
VPT の学習手順を図1に示す.図 1 にあるように学習は 3 ステップで行われる.以下で各ステップについて述べる.
ラベルなし動画に対して行動ラベルを付与するために,状態から行動を予測する IDM を少量のエキスパートデータで学習する.模倣学習は過去のフレームのみから行動を予測するのに対し,IDM は未来のフレームも用いて行動を予測するモデルである.例えば元論文 [1] の Minecraft に対する実験では, 128 フレーム分のシーケンスを入力して各フレームの行動を予測する.ただしシーケンスの両端は他ステップに関する情報が足りないため,中央の 64 フレームの予測結果を擬似ラベルとして用いる.
ステップ 1 で学習した IDM を用いてラベルなし動画に対して行動ラベルを予測する.予測された行動と動画データのセットから Agent の方策を模倣学習する.
ステップ 2 で模倣学習した Agent を Actor-Critic 法の一つである PPG で追加学習する.PPG は Proximal Policy Optimization (PPO) [3] のサンプル効率を改善した手法である.方策は同じサンプルを何度も学習することによる過適合が起こりやすいが,価値関数はその影響が少ない.そこで PPG は方策を学習するフェーズと価値関数を学習するフェーズに分け,それぞれで異なる最適化プロセスを行うことで,方策の過適合を防ぎつつ価値関数のサンプル効率を改善している.
また事前に模倣学習したモデルに対して強化学習による追加学習を行うと,精度が大幅に低下する破滅的忘却が起こることが知られている.これを防ぐために,事前学習済みモデルの方策と強化学習モデルの方策との KL loss を追加する.学習初期は KL loss の割合を大きくすることで事前学習済みモデルの方策を重視し,徐々に減らしていくことで破滅的忘却を防ぎつつ追加学習を可能にしている.

本実験では PPG と VPT を比較することで,VPT によるラベルなしデータを用いた模倣学習により,効率的な探索が可能か確認する.実験環境は OpenAI Gym [4] で公開されている Atari 2600 のゲームを用いる.
ステップ 1 の IDM の学習には,行動ラベルがついた人間のエキスパートデータセットが必要なため,Atari Grand Challenge データセット (AGC データセット) [7] を用いる.またステップ 2 の Agent の模倣学習には Atari-HEAD データセット [8] の動画を用いる.Atari 2600 の公開データセットには強化学習エージェントが収集したデータセットも存在するが, Web 動画からの模倣を想定していることから人間がプレイしたデータセットを用いた.
実験で用いるゲームは,AGC データセットと Atari-HEAD データセットの2つに共通して含まれている Ms.Pacman ,Space Invaders ,Montezuma’s Revenge の 3 つとする.各ゲームで 1 度に取れる行動の種類は Ms.Pacman が 9 種類 ,Invaders が 6 種類 ,Montezuma’s Revenge が 18 種類 である.
以下に各ステップに対する実験概要を示す.
ステップ 1 では少量のエキスパートデータで IDM を学習する.そこで学習回数 (Iteration) に対する IDM の予測精度で評価する.
IDM のネットワーク構造は,Residual Block [5] を用いた 10 層の畳み込み層と 2 層の全結合層から構成される.入力は大きさ 96 × 96 のグレースケール画像を 40 フレームのシーケンスとして入力し,各フレームに対する行動を予測するように学習する.学習時のハイパーパラメータは,Adam Optimizer [6] の学習率を 0.0001, Weight decay を 0.0 に変更している以外は [1] と同様である.
各ゲームの学習に用いる AGC データセットのデータ数は,Ms.Pacman が 1,481,325 フレーム,Space Invaders が 1,261,659 フレーム,Montezuma’s Revenge が 1,310,351 フレームである.
ステップ 2 では学習した IDM でラベル付けした動画データで Agent の方策を模倣学習する.そこで Agent を模倣学習した際の学習回数 (Iteration) に対する獲得スコアで評価する.
IDM でラベルなし動画に対して行動ラベルを予測する際,IDM に入力する 40 フレーム中,中央 20 フレームのみを Agent の模倣学習に用いる.
Agent のネットワーク構造は Policy Network ,Value Network 共に 3 層の畳み込み層と 2 層の全結合層で構成される.入力は 96 × 96 のグレースケール画像を 4 フレーム
分とする.模倣学習時のハイパーパラメータは,IDM の学習時と同様である.
各ゲームに用いる Atari-HEAD データセットのデータ数は,Ms.Pacman が 315,000 フレーム,Space Invaders が 365,828 フレーム,Montezuma’s Revenge が 364,371 フレームである.
ラベルなしの動画データとして Atari-HEAD データセットを用いるが,このデータセットには実際に人間がプレイした際の行動ラベルも含まれている.IDM のラベル付けが模倣学習にもたらす影響を確認するため,これらの行動ラベルを用いて模倣学習した場合との比較も行う.
ステップ 3 では,ステップ 2 で模倣学習した Agent を PPG で追加学習する.そこで Agent が環境とのインタラクションに費やしたステップ (グローバルステップ) 数が \(1.5 \times 10^7\) (15M) に到達したときに,100 エピソードのテストプレイをして獲得したスコアの平均で評価する.事前の模倣学習を行なっていない PPG と比較することで,VPT による模倣学習の有効性を確認する.
追加学習時のハイパーパラメータは,PPG 固有のものは [2] の付録 A.1 と同様とし,その他のものは [3] の付録 A の表 4 と同様とする.また PPG は乱数シードによる結果の変化が大きいため,乱数シードを変えて各 5 ゲームずつ行う.
各ステップに対する実験結果を以下に示す.
まずステップ 1 で学習した IDM の予測精度を確認する.
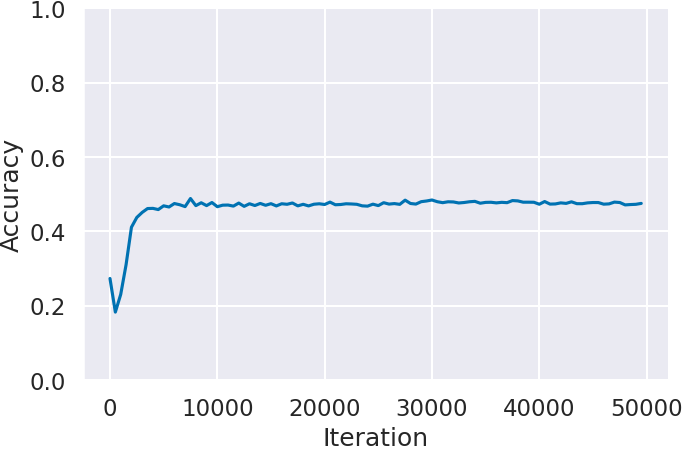
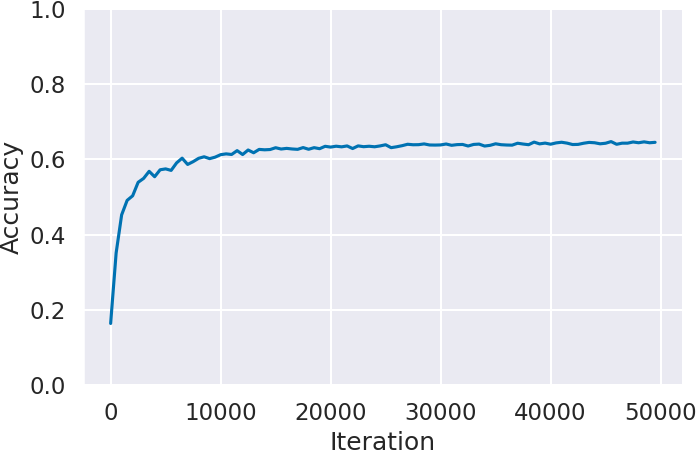
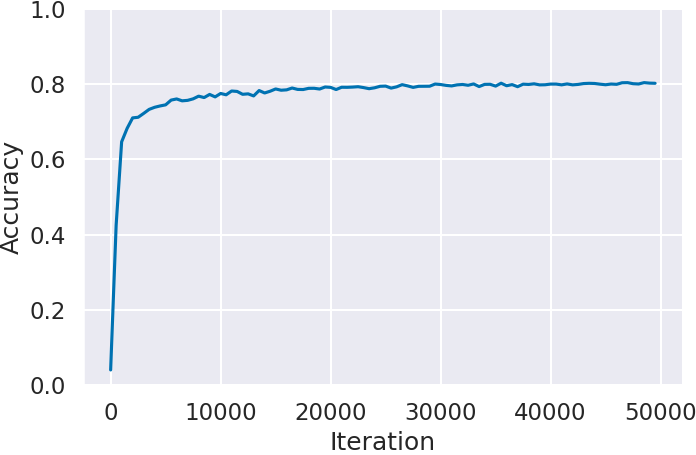
図 2 に各ゲームにおける学習回数 (Iteration) に対する IDM の予測精度 (Accuracy) を示す.Atari 2600 で最も複雑で攻略が難しいと言われている Montezuma’s Revenge (図2(c)) が約 80% で最も高い.それに次いで Space Invaders (図2(b)) が約 62% ,Ms.Pacman (図2(a)) に関しては約 45% と Montezuma’s Revenge (図2(c)) の半分程度の精度となった。この精度差はゲームごとの行動に対する状態 (画面) の変化の仕方の違いが影響していると考えられる.例えば Ms.Pacman では,入力された方向へ移動できない場合,キャラクターは入力される以前に進行していた方向に前進を続ける.つまり行動を入力してもキャラクターに変化が起きない.IDM は過去と未来の状態,つまり行動に対する画面上の動きから人間の行動を予測するため,このような場面が多いゲームでは精度が落ちてしまう.その結果,入力した通りにキャラクターが動かない場面が多い Ms.Pacman は精度が低くなり,反対にこのような場面が少ない Montezuma’s Revenge は高くなったと考えられる.
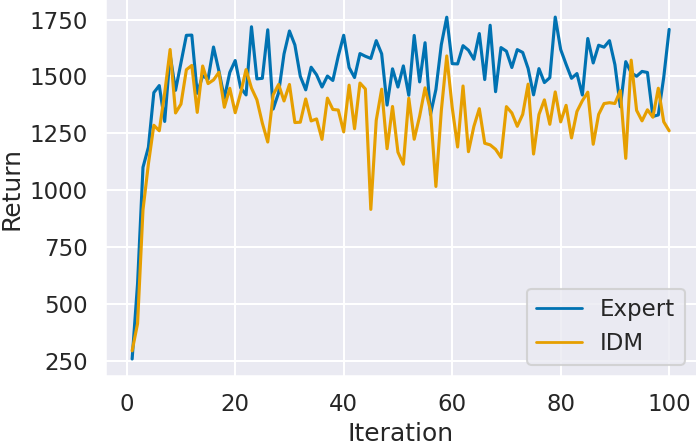
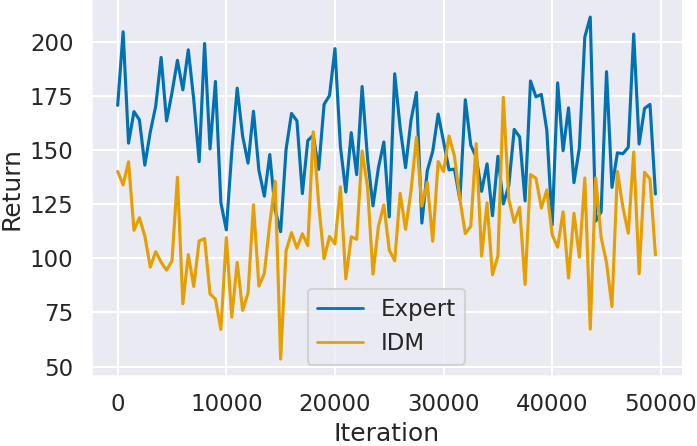
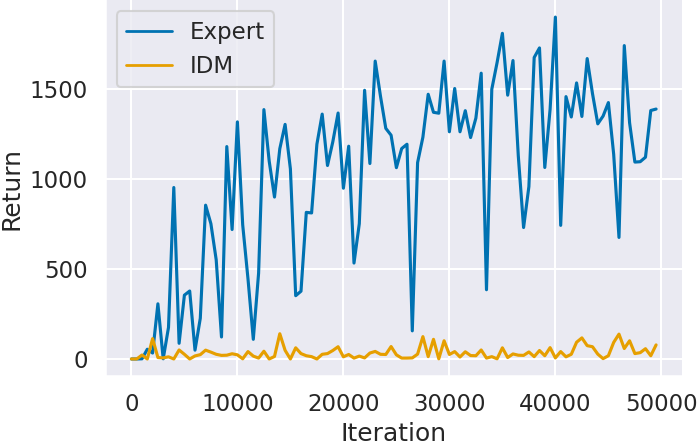
次にステップ 2 で模倣学習した Agent の獲得スコアの推移を確認する.実験概要で述べたように,IDM が予測したラベルで模倣学習した Agent (IDM) と,エキスパートデータのラベルで模倣学習した Agent (Expert) を比較することで,IDM のラベル付けが模倣学習にもたらす影響を確認する.
図 3 に各ゲームにおける学習回数 (Iteration) に対するAgentの獲得スコア (Return) を示す.どのゲームにおいても IDM のラベルで模倣学習した Agent (IDM) よりも,エキスパートデータのラベルで模倣学習した Agent (Expert) の方が高いスコアを獲得していることがわかる.特に Montezuma’s Revenge (図3(c)) では,IDM のラベルで学習した Agent はほとんどスコアが獲得できていないことがわかる.Montezuma’s Revenge は Atari 2600 で最も攻略が難しいゲームとして知られており,少しのミスでゲームオーバーとなる.そのため,IDM が予測できなかった場面が他のゲームよりも大きく影響しスコアが獲得できなかったと考えられる.
一方で,IDM の予測精度が Montezuma’s Revenge よりも低かった Ms.Pacman (図3(a)) や Space Invaders (図3(b)) は,エキスパートデータから模倣学習した Agent と近いスコアを獲得している.特に Ms.Pacman (図3(a)) は IDM の予測精度が約 45% であり、半分以上の場面を予測できていないにも関わらずスコアが獲得できている.ステップ 1 の結果で述べたように,IDM の予測精度が低下したのは行動に対してキャラクターや画面に変化が起きないことが原因である.このことから,画面の変化の違いによる IDM の精度低下は Agent の模倣学習の結果にほとんど影響しないと考えられる.また Space Invaders (図3(b)) は,どちらの Agent もほとんどスコアの向上が見られない.これは模倣学習ではスコアに表れる行動を獲得できなかったと考えられる.
最後にステップ 3 で追加学習した Agent の獲得スコアを確認する.
図 4 に追加学習時の各ゲームにおけるグローバルステップ数 (Step) に対する Agent の獲得スコア (Return) を示す.グラフは 5 seed 分の平均とその 95% 信頼区間で表される.どのゲームにおいてもグローバルステップ数を重ねるごとに,VPT の獲得スコアが事前の模倣学習を行っていない PPG と比べ向上している.特に Space Invaders と Montezuma’s Revenge は,ステップ 2 の模倣学習ではスコアの向上が見られなかったにも関わらず,VPT が PPG よりも高いスコアを獲得している.これはスコアには表れないものの強化学習のベースとなる方策を模倣学習によって獲得し,質の高い経験を収集できたからだと考えられる.
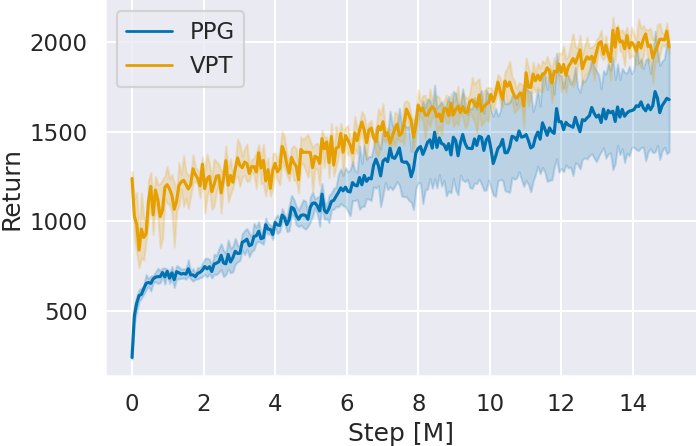
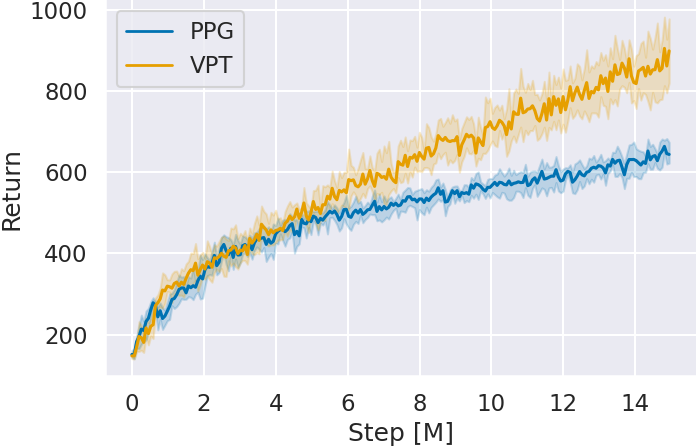
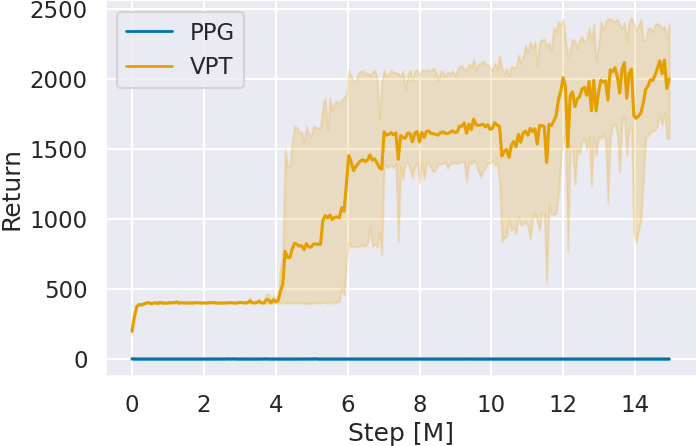
また,15M グローバルステップ時点における各ゲームに対する獲得スコアを確認すると,どのゲームにおいても VPT がより高いスコアを獲得している.
| Ms.Pacman | Space Invaders | Montezuma’s Revenge | |
|---|---|---|---|
| PPG | 1631.12 ± 260.96 | 642.75 ± 28.90 | 0.0 ± 0.0 |
| VPT | 2044.02 ± 86.43 | 898.75 ± 90.45 | 1998.0 ± 462.49 |
以上から,VPT はラベルなしデータを用いた模倣学習を行うことで PPG と比べ効率的に学習できることがわかる.
Atari 2600 の Ms.Pacman ,Space Invaders ,Montezuma’s Revenge について VPT の再現実験を行なった.PPG と比べて獲得スコアが向上したことから,VPT による模倣学習が有効であることを確認した.VPT は破滅的忘却を防ぐために KL loss を導入していたが,事前の模倣学習で用いた一部のデータを追加学習時にも用いるリプレイ法などを行うことで,より改善される可能性がある.
苦労した点としてハイパーパラメータの調整がある.元論文 [1] では Minecraft を対象に実験を行なっているため,同じものを使用してもうまく学習ができず,Atari 2600 に最適なものを見つける必要があった.特に PPG はハイパーパラメータの違いによる影響が大きかった.
今後は Atari 2600 よりも行動の選択肢が多いゲームや人間と対戦するゲームなど,より攻略難易度の高いゲームを学習することを考えている.また論文内では今後の展望として,動画に含まれる音声をテキストに変換し,Agent へ入力することで行動の条件付けが行えることを示唆している.しかし現状の結論としては,一部の条件は達成できるものの性能としては十分ではないと述べられているため,自然言語を組み合わせた手法も検討したいと考えている.
[1] B. Baker, I. Akkaya, P. Zhokov, J. Huizinga, J. Tang, A. Ecoffet, B. Hougton, R. Sampedro and J. Clune, Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos, Neural Information Processing Systems (NeurIPS) (2022). https://proceedings.neurips.cc/paper_files/paper/2022/hash/9c7008aff45b5d8f0973b23e1a22ada0-Abstract-Conference.html
[2] K. Cobbe, J. Hilton, O. Klimov and J. Schulman, Phasic Policy Gradient, International Conference on Machine Learning (ICML) (2021). https://icml.cc/virtual/2021/oral/8476
[3] J. Schulman, F. Wolski, P. Dhariwal, A. Radford and O. Klimov, Proximal Policy Optimization Algorithms, arXiv, preprint arXiv:1707.06347 (2017). https://arxiv.org/abs/1707.06347
[4] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang and W. Zaremba, OpenAI Gym, arXiv, preprint arXiv:1606.01540 (2016). https://www.gymlibrary.dev
[5] V. Kurin, S. Nowozin, K. Hofmann, L. Beyer, and B. Leibe, The Atari Grand Challenge Dataset, arXiv preprint arXiv:1705.10998 (2017). https://arxiv.org/abs/1705.10998
[6] R. Zhang, C. Walshe, Z. Liu, L. Guan, K. Muller, J. Whritner, L. Zhang, M. Hayhoe, and D. Ballard, Atari-HEAD Atari Human Eye-Tracking and Demonstration Dataset, Association for the Advancement of Artificial Intelligence (AAAI) (2020). https://ojs.aaai.org/index.php/AAAI/article/view/6161
[7] K. He, X. Zhang, S. Ren and J. Sun, Deep residual learning for image recognition, In Proceedings of the IEEE conference on computer vision and pattern recognition, Computer Vision and Pattern Recognition (CVPR) (2016). https://ieeexplore.ieee.org/document/7780459
[8] D. Kingma and J. Ba, A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014). https://arxiv.org/abs/1412.6980

Takuya Murase