This article is automatically translated.

We implemented the reinforcement learning system “SPIRAL” [1] announced by DeepMind using ChainerRL. The implementation is available on GitHub repository.
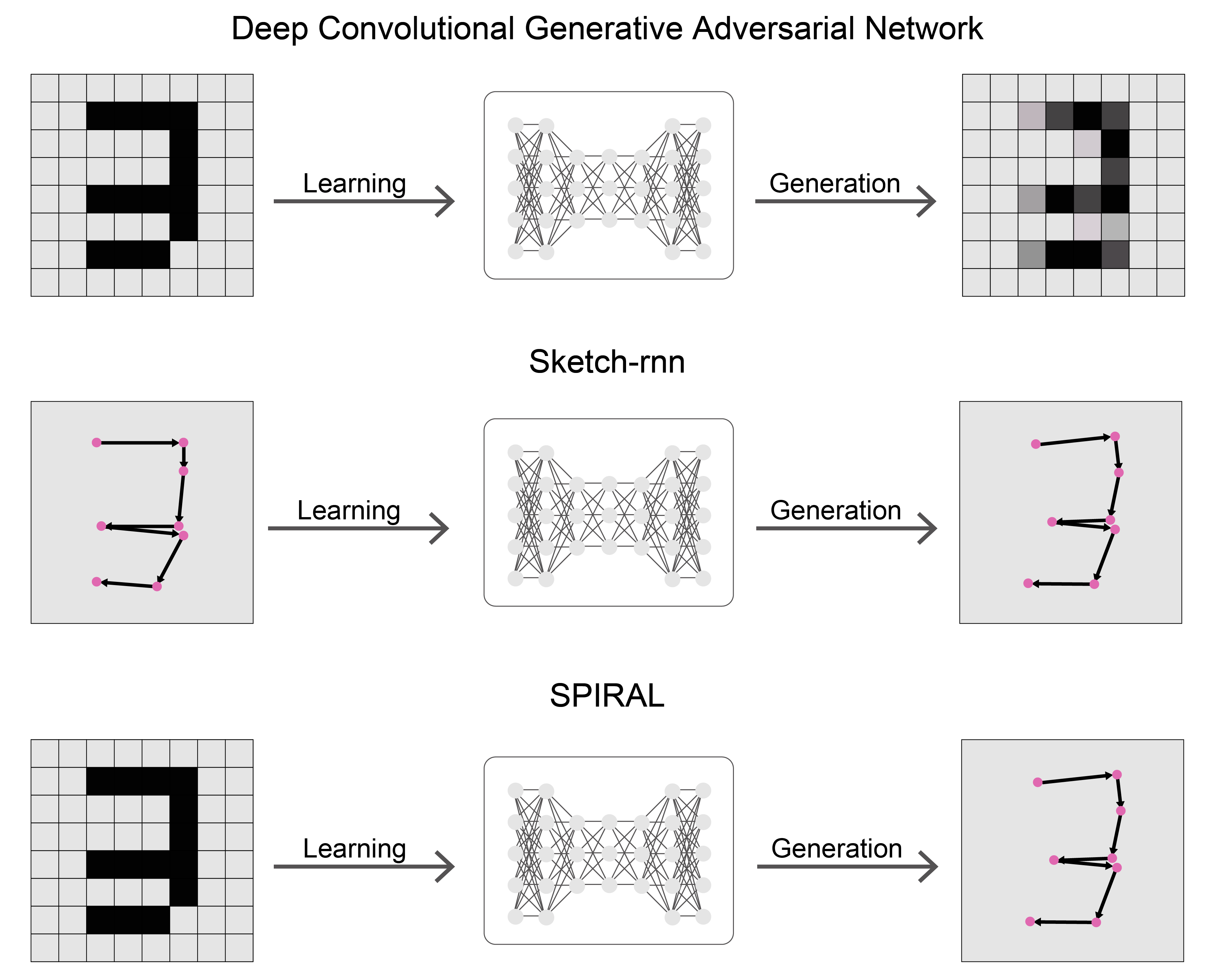
SPIRAL is a system for generating drawing methods from images. When it comes to image generation, Deep Convolutional Generative Adversarial Network (DCGAN [2]) is the main method, but while DCGAN generates raster images, SPIRAL can generate images in vector format through a series of drawing actions. Unlike raster images, vector images can be easily edited, such as removing specific lines. Sketch-rnn [3] is another model that generates vector images, but this model requires a large amount of drawing process data (i.e., vector data) for training. In contrast, SPIRAL only uses raster images for training.

SPIRAL performs drawing on a canvas for a certain number of steps, exploring how to draw pictures to maximize the similarity between the drawn image and the target (teacher data) image. The exploration is done through reinforcement learning, and the output of the discriminator, which estimates the distance between the drawn image and the target image, is used as a reward. By adversarially training the discriminator with the agent’s exploration, dynamic rewards are given, leading to more efficient convergence compared to using mean squared error.

By using the trained generation model, we can obtain generated images. The demo below shows the drawing process randomly selected from the generated drawing sequences.
Unlike DCGAN, the rendering process from drawing actions estimated by the deep learning model to image generation does not need to be differentiable. Therefore, it can be applied to various tasks that generate static images from a series of commands. For example, in the proposed paper, experiments are conducted to place objects in a simulation environment to create specified images. This time, we implemented the line drawing learning task using drawing software as experimented in the paper.
You can replay the drawing results of the SPIRAL agent trained with our reimplementation:

Click the button of the dataset name to start drawing. The pink circles plot the history of the pen position coordinates estimated by the model.
ChainerRL is a library that implements various reinforcement learning algorithms using the machine learning library Chainer. The paper uses an asynchronous learning pipeline called IMPALA [5] with a replay buffer. However, IMPALA was not implemented in ChainerRL. Therefore, we used Asynchronous Advantage Actor-Critic (A3C) [6], which was already implemented. A3C runs multiple CPU processes in parallel, each generating using the policy function, calculating rewards with the discriminator, and calculating gradients using the policy gradient method. Each process asynchronously updates the model parameters.
The implementation is available on GitHub. Models trained with MNIST, EMNIST, Quick, Draw!, and Classic Japanese Characters datasets are also published. The demo can be run in a Docker container. First, clone the repository:
git clone https://github.com/DwangoMediaVillage/chainer_spiral.gitThen build the Docker image:
cd chainer_spiral/docker
docker build . -t chainer_spiralNow you are ready to run the demo. You can see the generation results of the model trained with the Quick, Draw! dataset:
docker run -t --name run_chainer_spiral_demo chainer_spiral pipenv run python demo.py movie trained_models/quickdraw/68976000 result.mp4 --without_datasetCopy the generated video file from the container to the host to view it:
docker cp run_chainer_spiral_demo:/chainer_spiral/ChainerSPIRAL/result.mp4 .From the left, it shows the drawing process, the observation at the final time (the drawn picture), and the visualized drawing order (blue → red).

The drawing engine uses MyPaint, and it is designed to act as an environment for OpenAI Gym. ChainerRL assumes that the environment object calculates the rewards, but SPIRAL requires a neural network model as a discriminator for reward calculation. Therefore, the design allows the A3C agent to hold the discriminator model and calculate rewards.
When the agent explores, it sometimes finishes drawing without drawing anything. Therefore, we decided to introduce auxiliary rewards as per the paper. Since the specific reward design was not described, we decided to give negative rewards for finishing without drawing anything.
The point of problem settings for neural network generative models trained with gradient methods is whether everything from the data generation process to the loss function is differentiable. If the loss function is differentiable, gradient methods can be applied directly to regression problems targeting data. For example, in the case of DCGAN, the image is directly generated as a vector of pixel values, and the loss function is differentiable because a discriminative model is used. However, differentiable cases are limited. Drawing software can be seen as a function that generates images from drawing commands, but this function is generally not differentiable. Drafting, typesetting, music production, game design, etc., most of the generation processes we deal with are not differentiable except for very limited conditions.
If not differentiable, the problem setting needs to be changed to apply gradient methods. In SPIRAL, the generation process of drawing actions (vector) → image (raster) was not differentiable. Therefore, reinforcement learning is necessary. By replacing the evaluation function with a function that gives rewards, policy gradient methods can be applied directly to the generative model to maximize the evaluation value. This method greatly expands the possible formats that generative models can handle. However, there is a side effect that learning efficiency is sacrificed because gradients from the generated data do not propagate to the generative model.
Another method is to approximate the generation process with a differentiable model. For drawing, there is a proposed method to use a model that approximates the rendering function that generates raster images from drawing actions [https://openreview.net/forum?id=HJxwDiActX]. If the rendering approximation accuracy is sufficient, it is expected to be more efficient than exploration, but it is challenging to create a good approximation model in practice.
Implementing reinforcement learning experiments is difficult to achieve proper performance because it involves many asynchronous processes. ChainerRL abstracts and implements multiple reinforcement learning pipelines, so we could leave the implementation of process parallelization to the library, which shortened the development time.

Learning was very challenging. This is a common issue with reinforcement learning, but the difficulty lies in parameter search and reward design. There are limited combinations of parameters that can be tried, and the learning results often varied greatly depending on the parameter settings. Especially for auxiliary reward design, there is still room for improvement. The most challenging part was the learning time, as the Classic Japanese Characters dataset took more than 20 days (!) with 24 process parallelization. It seems that not only auxiliary rewards but also methods to efficiently explore, such as sampling states from a small number of drawing process data, are needed.
[1] Ganin, Y., Kulkarni, T., Babuschkin, I., Eslami, S.M.A. & Vinyals, O.. (2018). Synthesizing Programs for Images using Reinforced Adversarial Learning. Proceedings of the 35th International Conference on Machine Learning. http://arxiv.org/abs/1804.01118
[2] Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, Proceedings of the 4th International Conference on Learning Representations. http://arxiv.org/abs/1511.06434
[3] Ha, D., & Eck, D. (2017). A Neural Representation of Sketch Drawings. https://arxiv.org/abs/1704.03477
[4] Cohen, G., Afshar, S., Tapson, J., & van Schaik, A. (2017). EMNIST: an extension of MNIST to handwritten letters. http://arxiv.org/abs/1702.05373
[5] Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., Dunning, I., Legg, S. & Kavukcuoglu, K.. (2018). IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures. Proceedings of the 35th International Conference on Machine Learning. http://arxiv.org/abs/1802.01561
[6] Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T. P., Harley, T., … Kavukcuoglu, K. (2016). Asynchronous Methods for Deep Reinforcement Learning, Proceedings of the 35th International Conference on Machine Learning. http://arxiv.org/abs/1602.01783

Kazuma Sasaki