
DeepMindから発表された画像から描き方を生成する強化学習システム「SPIRAL」[1]をChainerRLを用いて実装した.実装はGitHubレポジトリで公開している.
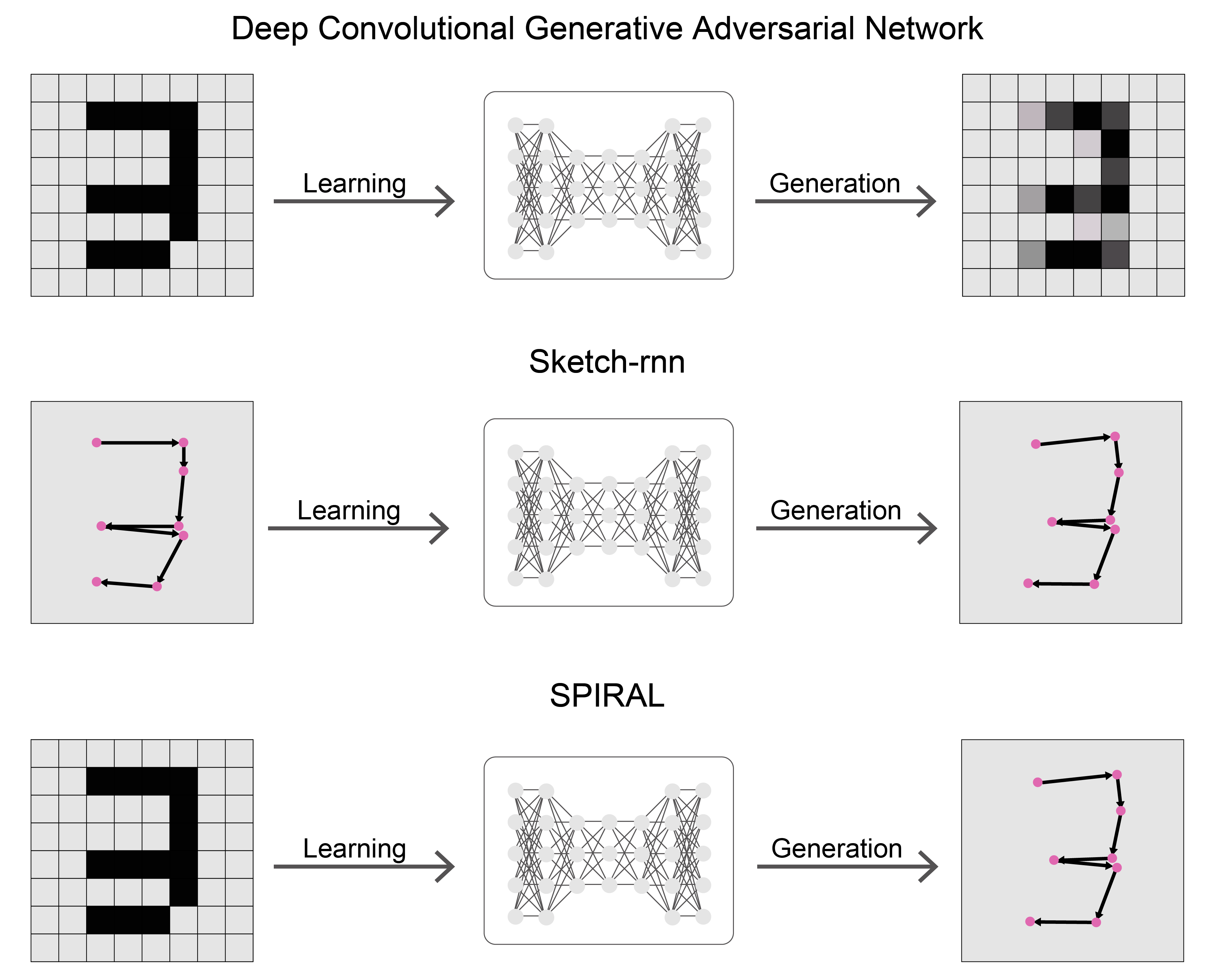
SPIRALは絵の画像から描き方を生成するためのシステムである.画像生成といえばDeep Convolutional Generative Adversarial Network(DCGAN [2])が主な手法だが,DCGANはラスター画像を生成するのに対して,SPIRALは時系列の描画行動,つまりベクター形式で画像を生成することができる.ベクター形式の画像はラスター形式とは異なり特定の線を取り除くといった編集を簡単に行うことができる.ベクター画像を生成するモデルとしてはSketch-rnn [3]があるが,このモデルは学習に描画過程,つまりベクター形式のデータが大量に必要になる.これらに対してSPIRALは学習にラスタ画像のみを使うという特徴がある.

SPIRALはキャンバスに一定のステップ数の間描画を行い,描かれた画像と手本(教師データ)となる画像との近さを最大化するように絵の描き方を探索する.探索は強化学習で行われ,描かれた絵とお手本画像の距離を推定するための判別器の出力を報酬とする.エージェントの探索と共に敵対的に判別器の学習をすることで動的に報酬が与えられ,二乗誤差を使うよりも効率的に収束する.

学習済み生成モデルのみを使って実際に描画させることで生成画像を得ることができる.以下に示すデモは生成された描画過程をランダムに選んで再生するものである.
DCGANとは異なり,深層学習モデルの推定する描画行動から絵の画像を作るレンダリング過程が微分可能である必要がない.そのため時系列のコマンドから静的な画像を生成するような様々なタスクへの応用が期待できる.たとえば,提案論文では実験されているようなシミュレーション環境にオブジェクトを配置して指定の画像のように作るタスクが実験されている.今回は論文で実験されているお絵かきソフトを用いた線描画学習タスクを実装した.
我々の追実装で学習したSPIRALエージェントの描画結果を再生することができる:

データセット名のボタンをクリックすると描画を開始する.ピンクの丸はモデルが推定したペンの位置座標の履歴をプロットしたものである.
ChainerRLは機械学習ライブラリChainerを使って様々な強化学習アルゴリズムを実装したライブラリである.論文ではIMPALA [5]と呼ばれるReplay Bufferを利用した非同期の学習パイプラインを使っている.しかしChainerRLにはIMPALAが実装されていなかった.そこで今回は既に実装されている Asynchronous Advantage Actor-Critic(A3C) [6]を利用することにした.A3Cでは複数のCPUプロセスを並列化で実行し,各々プロセスで方策関数を使った生成,判別器による報酬計算,方策勾配法を使った勾配計算を行う.そしてモデルのパラメーターは各々のプロセスが非同期に更新を行う.
実装はGitHubで公開している.MNIST,EMNIST,Quick, Draw!,古典籍字形それぞれのデータセットで学習させたモデルも合わせて公開している.デモの実行はDockerのコンテナ上で実行することができる.まずはレポジトリをクローンする:
git clone https://github.com/DwangoMediaVillage/chainer_spiral.gitそしてDockerイメージをビルドする:
cd chainer_spiral/docker
docker build . -t chainer_spiralここまででデモ実行の準備ができた.Quick, Draw!データセットで学習済みのモデルの生成結果を見ることができる:
docker run -t --name run_chainer_spiral_demo chainer_spiralpipenv run python demo.py movie trained_models/quickdraw/68976000 result.mp4 --without_dataset生成された動画ファイルをコンテナからホストへとコピーすると実際に閲覧することができる:
docker cp run_chainer_spiral_demo:/chainer_spiral/ChainerSPIRAL/result.mp4 .左側から描画の様子,最終時刻における観測(描かれた絵),そして書き順を可視化したもの(青→赤)になっている.

絵のレンダリングエンジンはMyPaintを利用しており,単体でOpenAI Gymの環境として振舞うよう設計されている.ChainerRLは環境オブジェクトが報酬を計算する前提で設計されているが,SPIRALは報酬計算に判別器であるニューラルネットのモデルが必要となる.そこで判別器のモデルをA3Cエージェントが保持し報酬計算を行うよう設計を行った.
エージェントが探索を行う際に,何も描かないまま描画が終了してしまう場合がある.そのため論文に従って補助的な報酬を導入することにした.具体的な報酬設計は記述されていなかったため,今回は何も描かないまま終了することに対して負の報酬を与えることにした.
勾配法による学習を行うニューラルネット生成モデルの問題設定のポイントは「データの生成過程から損失関数までのすべてが微分可能であるかどうか」にある.データを直接対象として回帰の問題は損失関数が微分可能でさえあれば勾配法を適用することができる.たとえば,DCGANの場合は画像をピクセル値のベクトルとして直接生成し,損失関数は微分可能な判別モデルを使うため微分可能である.しかし微分可能な場合は限られている.お絵かきソフトは描画のためのコマンドから画像を生成する関数としてみることができるが,この関数は一般に微分することができない.製図,組版,音楽製作,ゲームデザイン,etc… 私たちが扱うほとんどの生成過程はごく限られた条件を除いて微分不可能である.
微分不可能な場合には問題設定を勾配法が適用できるように変える必要がある.SPIRALでは描画行動(ベクター)→絵の画像(ラスタ)という生成過程が微分不可能だった.そこで強化学習が必要になる.評価関数を報酬を与える関数と置き換えることで,生成モデルには評価値を直接最大化するための方策勾配法を適用できる.この手法は生成モデルが扱うことができる形式の可能性を大きく広げるものであると言える.しかし生成されたデータからの勾配が生成モデルに伝搬されないため学習効率が犠牲になるという副作用がある.
生成過程を微分可能なモデルで近似するという方法もある.描画でいえば描画行動からラスタ画像を生成するレンダリング関数を近似するモデルを利用する手法が提案されている.レンダリングの近似精度が十分であれば探索よりも効率的になることが予想されるが,実際によい近似モデルを作ることが難しいという課題もある.
強化学習実験の実装は非同期処理が多用されるためきちんとパフォーマンスが出るように実装することが難しい.ChainerRLは複数の強化学習のパイプラインを抽象化して実装しているため,プロセス並列化に関する実装はライブラリ任せにできたため開発時間を短縮することができた.

学習は非常に大変だった.その理由は強化学習全般に言える問題だが,パラメーター探索と報酬設計の難しさにある.試すことができるパラメーターの組み合わせ限りがある上に,学習結果がパラメーター設定によって大きく変わってしまうことが何度もあった.とくに補助報酬の設計についてはまだ改善の余地がある.そして何よりも大変だったのは学習時間で,日本古典籍字形データセットは24プロセス並列で20日以上(!)かかった.補助報酬だけではなく,少数の描画過程データから状態をサンプリングするなどの探索を効率化する方法が必要そうだと感じた.
[1] Ganin, Y., Kulkarni, T., Babuschkin, I., Eslami, S.M.A. & Vinyals, O.. (2018). Synthesizing Programs for Images using Reinforced Adversarial Learning. Proceedings of the 35th International Conference on Machine Learning. http://arxiv.org/abs/1804.01118
[2] Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, Proceedings of the 4th International Conference on Learning Representations. http://arxiv.org/abs/1511.06434
[3] Ha, D., & Eck, D. (2017). A Neural Representation of Sketch Drawings. https://arxiv.org/abs/1704.03477
[4] Cohen, G., Afshar, S., Tapson, J., & van Schaik, A. (2017). EMNIST: an extension of MNIST to handwritten letters. http://arxiv.org/abs/1702.05373
[5] Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., Dunning, I., Legg, S. & Kavukcuoglu, K.. (2018). IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures. Proceedings of the 35th International Conference on Machine Learning. http://arxiv.org/abs/1802.01561
[6] Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T. P., Harley, T., … Kavukcuoglu, K. (2016). Asynchronous Methods for Deep Reinforcement Learning, Proceedings of the 35th International Conference on Machine Learning. http://arxiv.org/abs/1602.01783

Kazuma Sasaki