This article is automatically translated.
While reinforcement learning requires a vast number of trials to learn an appropriate policy, it is known that combining it with imitation learning can reduce exploration costs. However, imitation learning requires a labeled dataset, making data collection costly. Video PreTraining (VPT), presented at NeurIPS 2022 [1], performs semi-supervised imitation learning from unlabeled videos, which are relatively inexpensive to collect, thereby reducing data collection costs. In this experiment, we applied VPT to the Atari 2600 games, a well-known reinforcement learning benchmark, to confirm its effectiveness.
VPT proposes to learn from human gameplay videos without action labels, which are less costly to collect. It uses an Inverse Dynamics Model (IDM) to predict pseudo-action labels from the state and applies imitation learning. This approach achieved the first-ever successful completion of the diamond pickaxe collection task in Minecraft, which was previously unattainable with traditional reinforcement learning or imitation learning.
The learning procedure of VPT is shown in Figure 1. As shown in Figure 1, the learning process consists of three steps, which are described below.
To assign action labels to unlabeled videos, IDM is learned with a small amount of expert data. Unlike imitation learning, which predicts actions from past frames, IDM predicts actions using future frames. For instance, in the experiment for Minecraft presented in the original paper [1], a sequence of 128 frames is input, and actions for each frame are predicted. The central 64 frames are used as pseudo labels due to insufficient information at the sequence’s edges.
Using the learned IDM, action labels are predicted for unlabeled videos, and the agent’s policy is trained by imitation learning with the predicted actions and video data.
The agent trained by imitation learning in Step 2 undergoes additional training using PPG, an actor-critic method. PPG improves the sample efficiency of Proximal Policy Optimization (PPO) [3]. Policies tend to overfit when trained repeatedly with the same samples, whereas value functions are less affected. PPG separates the phases of policy and value function learning, optimizing them with different processes to prevent policy overfitting and improve value function sample efficiency.
To prevent catastrophic forgetting when additional learning is applied to pre-trained models, KL loss between the pre-trained model’s policy and the reinforcement learning model’s policy is added. Initially, the KL loss weight is large to emphasize the pre-trained model’s policy and gradually decreases to enable additional learning while preventing catastrophic forgetting.

In this experiment, we compare PPG and VPT to verify whether imitation learning using unlabeled data with VPT allows efficient exploration. The experimental environment involves the Atari 2600 games provided by OpenAI Gym [4].
Since labeled human expert data is required for IDM learning in Step 1, we use the Atari Grand Challenge dataset (AGC dataset) [7]. For the agent’s imitation learning in Step 2, we use the Atari-HEAD dataset [8]. Although datasets collected by reinforcement learning agents exist for Atari 2600, we use a dataset of human-played games to simulate imitation from web videos.
The games used in the experiment are Ms. Pacman, Space Invaders, and Montezuma’s Revenge, common to both the AGC dataset and the Atari-HEAD dataset. The number of actions available per game is 9 for Ms. Pacman, 6 for Space Invaders, and 18 for Montezuma’s Revenge.
The experimental overview for each step is as follows.
In Step 1, IDM is learned with a small amount of expert data, and its prediction accuracy is evaluated by the number of training iterations.
The network structure of IDM consists of ten convolutional layers with Residual Blocks [5] and two fully connected layers. The input is a sequence of 40 grayscale images with a size of 96 × 96, predicting actions for each frame. The hyperparameters during training are the same as in [1], except the Adam Optimizer [6] learning rate is set to 0.0001, and the weight decay is set to 0.0.
The number of frames used from the AGC dataset for each game is 1,481,325 for Ms. Pacman, 1,261,659 for Space Invaders, and 1,310,351 for Montezuma’s Revenge.
In Step 2, the agent’s policy is trained by imitation learning using the video data labeled by the learned IDM, and the score obtained by the agent is evaluated by the number of training iterations.
When IDM predicts action labels for unlabeled videos, only the central 20 frames of the 40-frame sequence input to IDM are used for the agent’s imitation learning.
The network structure of the agent consists of three convolutional layers and two fully connected layers for both the Policy Network and the Value Network. The input is four frames of 96 × 96 grayscale images. The hyperparameters during imitation learning are the same as those during IDM learning.
The number of frames used from the Atari-HEAD dataset for each game is 315,000 for Ms. Pacman, 365,828 for Space Invaders, and 364,371 for Montezuma’s Revenge.
Although the Atari-HEAD dataset contains action labels from actual human play, we compare imitation learning using these labels with the labels predicted by IDM to understand IDM’s labeling impact on imitation learning.
In Step 3, the agent trained by imitation learning in Step 2 undergoes additional training with PPG. The agent’s score is evaluated by the average score obtained from 100 test plays when the number of global steps (steps spent interacting with the environment) reaches \(1.5 \times 10^7\) (15M). We compare VPT with PPG without pre-imitation learning to verify the effectiveness of VPT imitation learning.
The hyperparameters during additional learning are the same as in [2]’s Appendix A.1 for PPG-specific ones and Table 4 in Appendix A of [3] for the others. As PPG results vary significantly with different random seeds, we conduct five games with different random seeds.
The experimental results for each step are shown below.
First, we confirm the prediction accuracy of IDM learned in Step 1.
Figure 2 shows the prediction accuracy of IDM for each game by the number of training iterations. Montezuma’s Revenge (Figure 2(c)), the most complex and challenging game on the Atari 2600, achieves the highest accuracy at approximately 80%. Space Invaders (Figure 2(b)) follows with about 62%, while Ms. Pacman (Figure 2(a)) has about 45%, roughly half the accuracy of Montezuma’s Revenge. This accuracy difference is thought to result from how each game affects the state (screen) changes with actions. In Ms. Pacman, if the input direction cannot be moved, the character continues moving in the previous direction, meaning actions do not always result in changes. IDM predicts human actions from the state changes (movement on the screen) caused by actions, so games with many such situations have lower accuracy. Thus, Ms. Pacman, where the character often does not move as input, has low accuracy, while Montezuma’s Revenge, with fewer such situations, has higher accuracy.
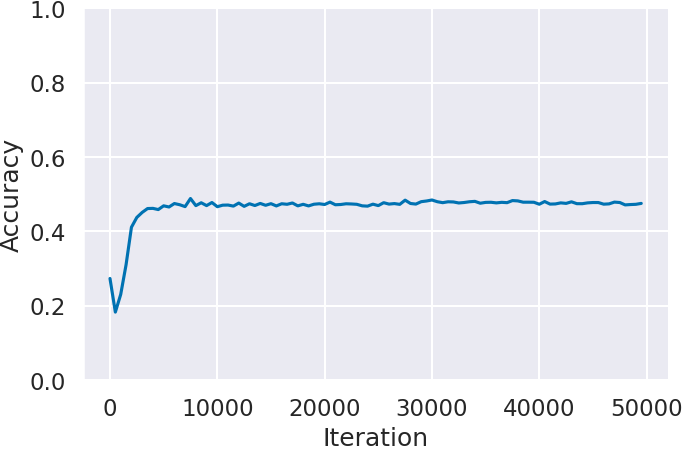
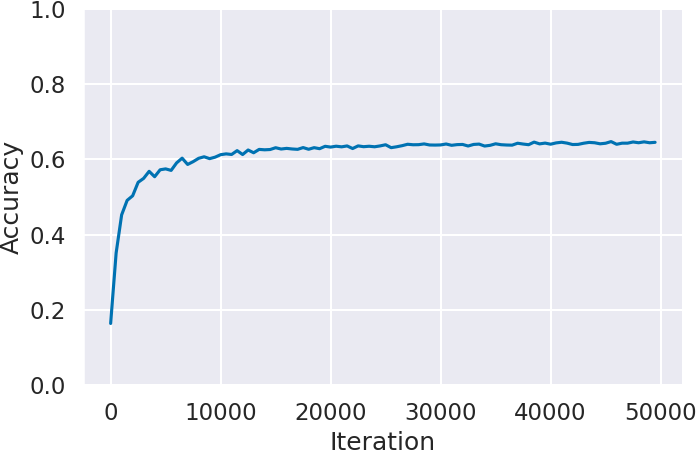
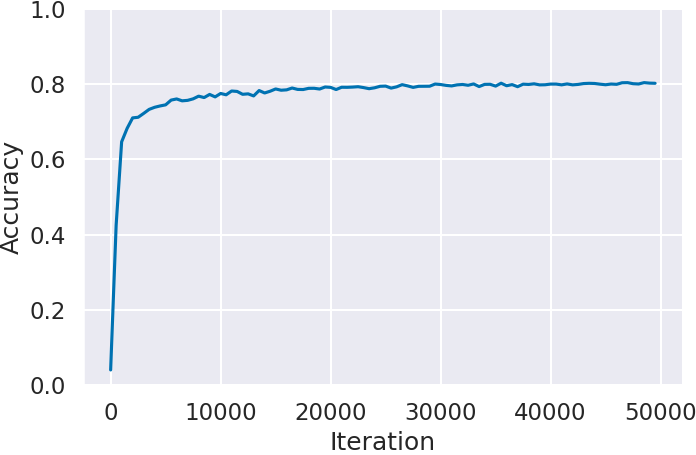
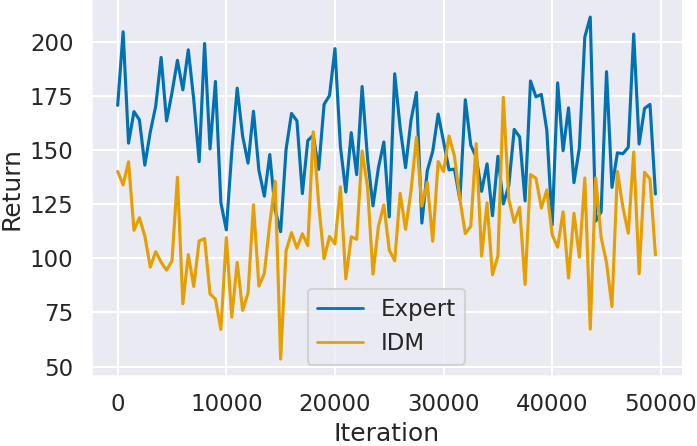
Next, we confirm the score transition of the agent trained by imitation learning in Step 2. By comparing agents trained with IDM-predicted labels (IDM) and expert data labels (Expert), we evaluate IDM’s labeling impact on imitation learning.
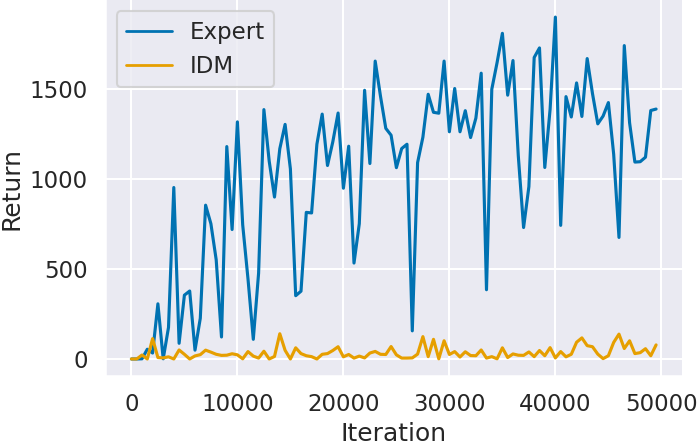
Figure 3 shows the agent’s scores (Return) for each game by the number of training iterations. In all games, agents trained with expert data labels (Expert) outperform those trained with IDM-predicted labels (IDM). Particularly in Montezuma’s Revenge (Figure 3(c)), agents trained with IDM labels hardly score
. Montezuma’s Revenge is known as the most challenging game on the Atari 2600, where even small mistakes result in game over. Thus, situations where IDM fails to predict actions significantly impact the score.
In contrast, Ms. Pacman (Figure 3(a)) and Space Invaders (Figure 3(b)), where IDM prediction accuracy was lower than Montezuma’s Revenge, achieve scores close to those of agents trained with expert data. Especially in Ms. Pacman (Figure 3(a)), scores are achieved despite IDM’s prediction accuracy being about 45%, failing to predict over half the situations. As mentioned in the Step 1 results, the lower IDM prediction accuracy resulted from situations where actions did not lead to state changes. Therefore, IDM’s accuracy decrease due to state change differences hardly affects imitation learning results. Additionally, in Space Invaders (Figure 3(b)), neither agent showed significant score improvement, suggesting imitation learning failed to acquire score-influencing actions.
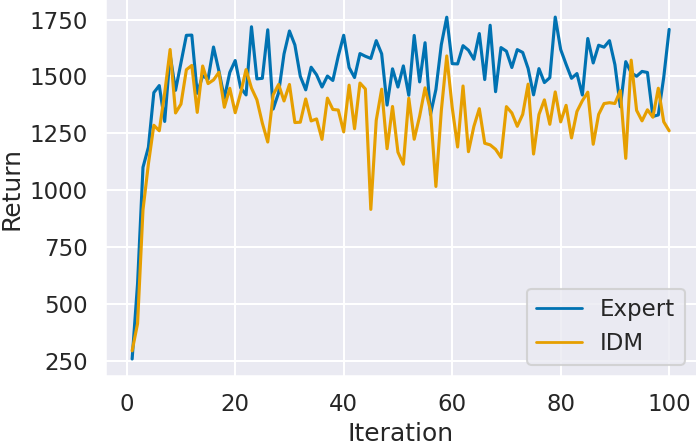
Finally, we confirm the scores of agents trained in Step 3.
Figure 4 shows the agent’s scores (Return) for each game by the number of global steps (Step) during additional learning. The graphs represent the average of five seeds and their 95% confidence intervals. In all games, VPT’s scores improve over PPG without prior imitation learning as the number of global steps increases. Particularly in Space Invaders and Montezuma’s Revenge, where imitation learning in Step 2 did not improve scores, VPT outperforms PPG. This suggests that imitation learning acquired a policy base for reinforcement learning, enabling quality experience collection despite not being reflected in scores.
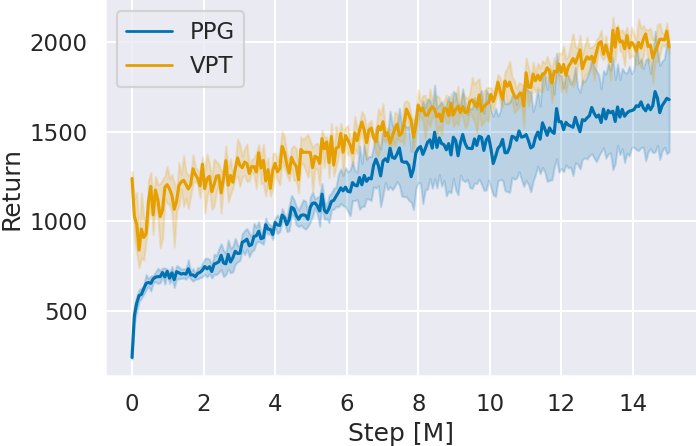
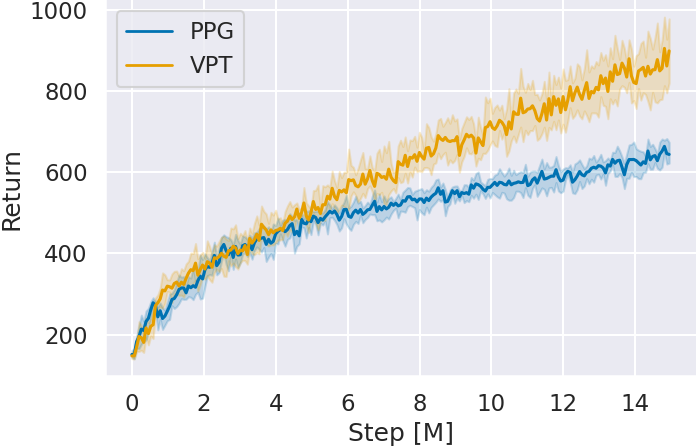
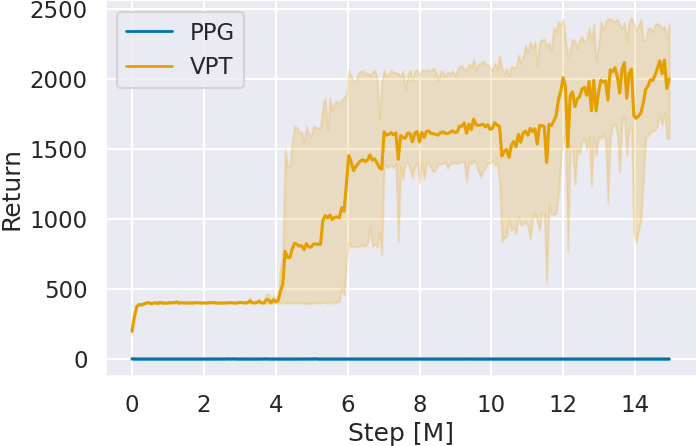
When confirming the scores at 15M global steps, VPT achieves higher scores in all games.
| Ms. Pacman | Space Invaders | Montezuma’s Revenge | |
|---|---|---|---|
| PPG | 1631.12 ± 260.96 | 642.75 ± 28.90 | 0.0 ± 0.0 |
| VPT | 2044.02 ± 86.43 | 898.75 ± 90.45 | 1998.0 ± 462.49 |
These results demonstrate that VPT enables efficient learning compared to PPG by performing imitation learning with unlabeled data.
We conducted reproduction experiments of VPT on Ms. Pacman, Space Invaders, and Montezuma’s Revenge for Atari 2600. The results showed that VPT’s imitation learning is effective, as evidenced by improved scores compared to PPG. Although VPT introduced KL loss to prevent catastrophic forgetting, methods such as replay, which reuse some data from prior imitation learning during additional learning, might offer further improvements.
Hyperparameter tuning was a challenging aspect. Since the original paper [1] experimented with Minecraft, using the same parameters did not yield successful learning, necessitating optimal parameters for Atari 2600. Particularly for PPG, hyperparameters significantly affected the outcomes.
Future work will consider learning games with more action choices than Atari 2600 or games involving human opponents, thus increasing the difficulty level. Additionally, the paper suggests that converting audio in videos to text for agent input could condition actions, hinting at combining natural language with current methods for future investigation. Although the current results indicate that some conditions are met, the performance is not yet satisfactory, warranting further exploration of methods combining natural language.
[1] B. Baker, I. Akkaya, P. Zhokov, J. Huizinga, J. Tang, A. Ecoffet, B. Hougton, R. Sampedro and J. Clune, Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos, Neural Information Processing Systems (NeurIPS) (2022). https://proceedings.neurips.cc/paper_files/paper/2022/hash/9c7008aff45b5d8f0973b23e1a22ada0-Abstract-Conference.html
[2] K. Cobbe, J. Hilton, O. Klimov and J. Schulman, Phasic Policy Gradient, International Conference on Machine Learning (ICML) (2021). https://icml.cc/virtual/2021/oral/8476
[3] J. Schulman, F. Wolski, P. Dhariwal, A. Radford and O. Klimov, Proximal Policy Optimization Algorithms, arXiv, preprint arXiv:1707.06347 (2017). https://arxiv.org/abs/1707.06347
[4] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang and W. Zaremba, OpenAI Gym, arXiv, preprint arXiv:1606.01540 (2016). https://www.gymlibrary.dev
[5] V. Kurin, S. Nowozin, K. Hofmann, L. Beyer, and B. Leibe, The Atari Grand Challenge Dataset, arXiv preprint arXiv:1705.10998 (2017). https://arxiv.org/abs/1705.10998
[6] R. Zhang, C. Walshe, Z. Liu, L. Guan, K. Muller, J. Whritner, L. Zhang, M. Hayhoe, and D. Ballard, Atari-HEAD Atari Human Eye-Tracking and Demonstration Dataset, Association for the Advancement of Artificial Intelligence (AAAI) (2020). https://ojs.aaai.org/index.php/AAAI/article/view/6161
[7] K. He, X. Zhang, S. Ren and J. Sun, Deep residual learning for image recognition, In Proceedings of the IEEE conference on computer vision and pattern recognition, Computer Vision and Pattern Recognition (CVPR) (2016). https://ieeexplore.ieee.org/document/7780459
[8] D. Kingma and J. Ba, A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014). https://arxiv.org/abs/1412.6980

Takuya Murase